Last Updated: May 18, 2026

Why Run Two Different AI Models Instead of One?
Most people assume you need one big, powerful model to do everything. We found the opposite works better. Running two specialised models on two separate machines gives you the best of both worlds: lightning-fast responses for everyday tasks and deep, careful reasoning when you need it.
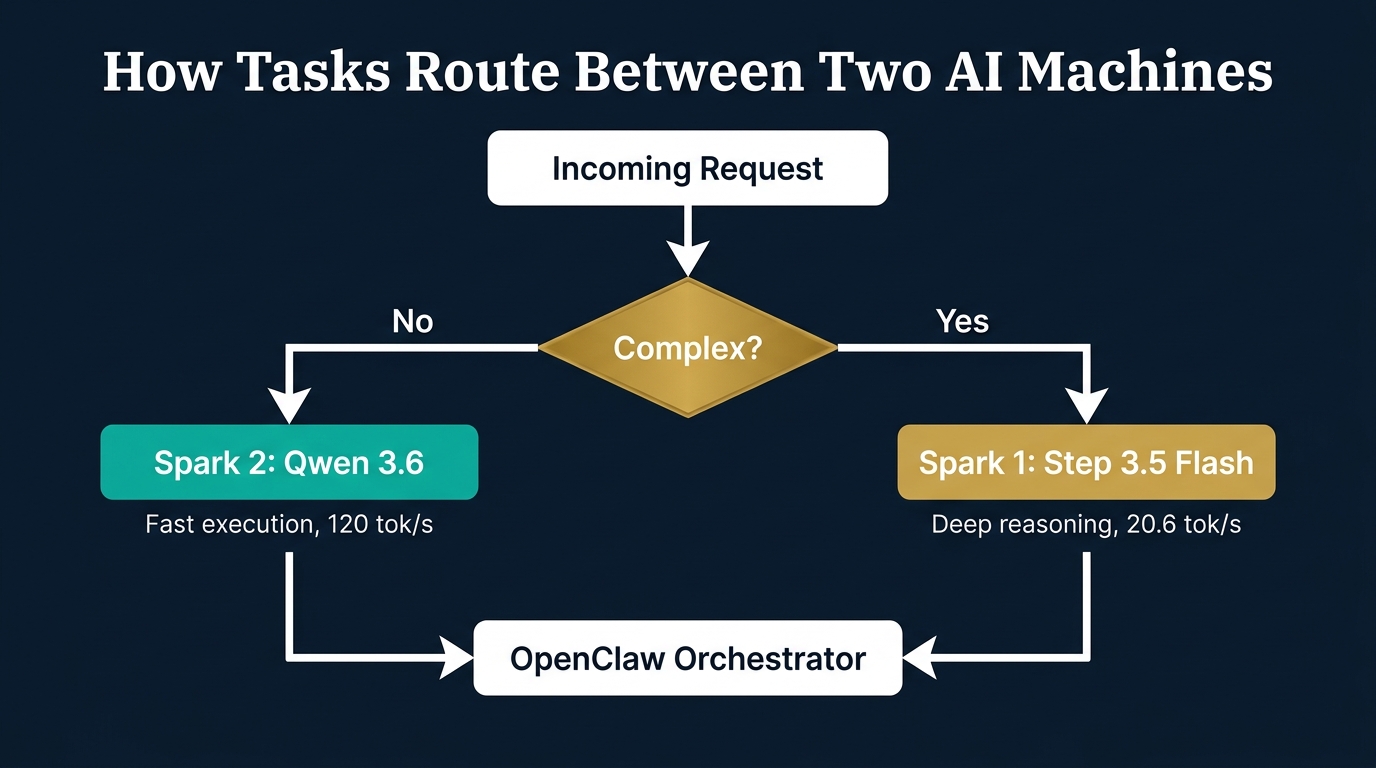
Our setup uses two NVIDIA DGX Sparks, each about the size of a hardcover book, sitting on a desk. One runs Qwen 3.6 at 120 tokens per second for fast work. The other runs Step 3.5 Flash at 20.6 tokens per second for complex reasoning. Together they cost roughly $18,000 AUD in hardware, with zero ongoing costs.
This is not a theoretical setup. It is running right now, serving real workloads privately, with no data ever leaving the building.

What Is Qwen 3.6 and Why Is It So Fast?
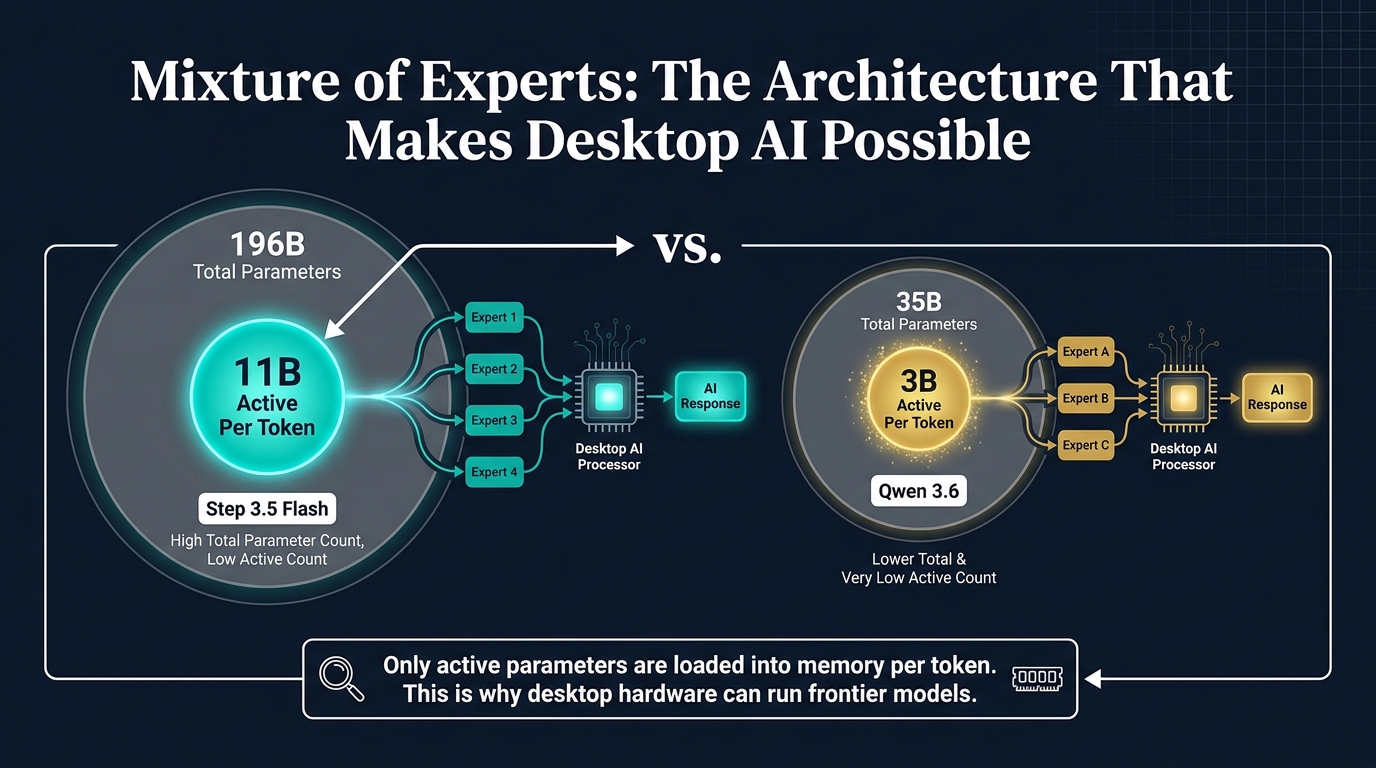
Qwen 3.6 35B-A3B is a mixture-of-experts model created by Alibaba and quantised to NVFP4 format by Red Hat AI. It has 35 billion total parameters but only activates 3 billion per token. That is the key to its speed.
On our second DGX Spark, running through the Atlas inference engine (a Rust-based server with custom CUDA kernels for NVIDIA Blackwell), Qwen 3.6 delivers 120 tokens per second with 1 million tokens of context. The speed does not degrade as you add more context. We tested from 16,000 tokens to 1 million tokens and saw less than 3 tokens per second difference across the entire range.
We use this model for tasks where speed matters most: tool calls, routing decisions, quick lookups, and interactive conversation. At 120 tok/s it produces roughly 90 words per second, which is faster than anyone can read.
Key specs:
- 35 billion total parameters, 3 billion active per token
- 120 tok/s sustained on DGX Spark via Atlas
- 1 million token context window
- 27 millisecond time to first token
- Supports text, image, video, and audio
- Apache 2.0 licence
What Is Step 3.5 Flash and Why Do We Use It?
Step 3.5 Flash is a mixture-of-experts model built by StepFun with 196 billion total parameters and 11 billion active per token. It is one of the most capable open-source models available right now. On the AIME 2025 mathematics benchmark it scores 97.3 per cent. On SWE-bench Verified (a coding benchmark) it scores 74.4 per cent.
We run it on our first DGX Spark through llama.cpp, an efficient C++ inference engine. At 20.6 tokens per second it is slower than Qwen, but that is by design. Step 3.5 Flash is for tasks where quality matters more than speed: complex reasoning chains, multi-step code analysis, research exploration, and strategic planning.
Key specs:
- 196 billion total parameters, 11 billion active per token
- 20.6 tok/s on DGX Spark via llama.cpp
- 256,000 token context window
- AIME 2025: 97.3 per cent (beats DeepSeek V3.2 and Kimi K2.5)
- SWE-bench Verified: 74.4 per cent
- Built-in multi-token prediction (MTP-3)
Why Not Just Run Qwen on Both Machines?
Qwen 3.6 is fast and capable, but it has limitations that matter for certain tasks. With only 3 billion active parameters per token, it cannot match the reasoning depth of a model with 11 billion active parameters on genuinely complex problems.
Think of it like a team. You want a fast worker who handles routine tasks efficiently, and you want a senior analyst who takes longer but produces deeper work when the problem is genuinely hard. Putting two fast workers on the team does not help when you need the analyst.
In practice, this means Step 3.5 Flash handles tasks like:
- Breaking down a complex codebase and identifying subtle bugs
- Working through multi-step mathematical proofs
- Analysing long research documents and synthesising arguments
- Planning multi-step agent workflows that require strategic decisions
Meanwhile, Qwen 3.6 handles:
- Executing tool calls and returning results quickly
- Routing incoming requests to the right handler
- Generating quick summaries and responses
- Running interactive conversations where latency matters
Why We Switched From DeepSeek to Step 3.5 Flash
We originally ran DeepSeek V4 Flash on Spark 1 using ds4, a custom inference engine purpose-built for 128GB hardware. It worked, delivering about 11.4 tok/s with a 2-bit quantised model.
The problem was quality. The 2-bit quantisation (called DwarfStar 4) compressed the model aggressively to fit in memory. At that level of compression, you start losing nuance. Complex reasoning tasks would occasionally produce simplified or incomplete answers because the model simply did not have enough precision in its weights.
Step 3.5 Flash solved this. With IQ4_XS quantisation (a smarter 4-bit scheme), it runs at nearly twice the speed while maintaining much higher weight fidelity. The AIME 2025 score of 97.3 per cent versus DeepSeek V3.2's 93.1 per cent tells the story. Step Flash is genuinely better at hard problems.
The switch also simplified our stack. Instead of a custom-built binary with specific model format requirements, Step 3.5 Flash runs through llama.cpp, a well-maintained open-source project with broad community support.
How Mixture of Experts Makes This Possible
Both models in our cluster use mixture-of-experts (MoE) architecture, and this is the single most important technology that makes desktop AI inference viable.
In a traditional dense model, every parameter is used for every token. A 35 billion parameter model loads all 35 billion parameters for each word it generates. On the DGX Spark with 273 GB/s of memory bandwidth, loading 35 billion parameters at 16-bit precision (70GB) takes long enough to limit you to about 3.7 tokens per second.
MoE models work differently. They have many parameters divided into "experts" (groups of parameters specialising in different types of content). For each token, a routing mechanism selects only the relevant experts. Qwen 3.6 has 35 billion total parameters but only uses 3 billion per token. Step 3.5 Flash has 196 billion but only uses 11 billion.
This means the memory bottleneck (how fast you can load weights from memory to the GPU) is determined by the active parameter count, not the total. You get the knowledge of a massive model with the speed of a small one.
For Qwen 3.6 in NVFP4 format, those 3 billion active parameters translate to roughly 10GB of weights per forward pass. Through the DGX Spark's 273 GB/s bandwidth, that loads fast enough for 120 tokens per second when combined with Atlas's optimised kernels.
The Total Cost of This Setup
For anyone considering building something similar, here is the full cost breakdown.
Hardware:
- 2x NVIDIA DGX Spark: roughly $7,900 AUD each ($15,800 total)
- 1x QSFP112 200G DAC cable: roughly $50 AUD (for future stacking)
- 1x TP-Link 5-port Ethernet switch: roughly $30 AUD
- Total hardware: approximately $15,880 AUD
Software:
- Atlas inference engine: open source (AGPL)
- llama.cpp: open source (MIT)
- Qwen 3.6 35B-A3B NVFP4: Apache 2.0
- Step 3.5 Flash GGUF: available from StepFun on Hugging Face
- Total software: $0
Ongoing costs:
- Electricity: roughly $200-400 per year for both machines (each draws about 150-200 watts under load)
- No API costs, no subscription fees, no data egress charges
What this replaces: If you processed 1 billion tokens per year through cloud APIs (a realistic figure for a business running multiple AI agents), you would spend roughly $15,000 to $30,000 per year on inference costs. This hardware pays for itself in under 18 months, and then it is free forever.
What This Means For Australian Businesses
This two-model architecture has specific implications for Australian businesses working with sensitive data.
Healthcare practices can run AI for clinical decision support without patient records ever leaving the building. The reasoning model (Step 3.5 Flash) can analyse complex cases while the speed model (Qwen 3.6) handles routine documentation and scheduling.
Legal firms can analyse contracts and case law privately. The deep reasoning capabilities of Step 3.5 Flash are well suited to legal analysis, while Qwen 3.6 handles client communication and document drafting.
Engineering firms can load entire project specifications, codebases, and technical standards into context. At 256K tokens of context on the reasoning engine, you can work with substantial documents in a single conversation.
Financial advisors can process sensitive client documents and generate reports without any data going to overseas servers. Both models run completely locally, with no internet connection required after initial setup.
The two-model approach means you are not forced to choose between speed and quality. Fast tasks get fast responses. Hard problems get the time they need.
How To Set This Up
If you have the hardware, the setup is straightforward.
Spark 1 (Reasoning):
- Install llama.cpp with CUDA support
- Download Step 3.5 Flash Q4_K_S GGUF from Hugging Face (about 90GB)
- Run llama-server with the model on port 8000
- Create a systemd service for auto-start
Spark 2 (Speed):
- Install Docker
- Pull the Atlas GB10 image (avarok/atlas-gb10:latest)
- Run with the Qwen 3.6 NVFP4 model and 1M context
- Create a systemd service for auto-start
Networking:
- Install Tailscale on both Sparks and your orchestrator machine
- Both models are now accessible via OpenAI-compatible API endpoints
- Route tasks based on complexity: fast tasks to Spark 2, reasoning to Spark 1
What We Learned Building This
Lesson 1: The inference engine matters more than the model. We saw a 2.4x speedup on the exact same model just by switching from vLLM (Python) to Atlas (Rust). The model did not change. The hardware did not change. Only the software layer between the request and the GPU changed.
Lesson 2: Quantisation format matters for specific hardware. NVFP4 is NVIDIA's native 4-bit format for Blackwell. Using generic Q4 quantisation works but leaves performance on the table. Matching the quantisation to the hardware gives you better quality at the same speed.
Lesson 3: Two specialised machines beat one general-purpose setup. We tested linking both Sparks via QSFP for a single larger model. The overhead of synchronising between machines across a network added latency that negated the benefit. Running independent models in parallel is the better architecture for interactive workloads.
Lesson 4: Mixture of experts is the key to desktop AI. Without MoE, a 35B model loads all 35B parameters per token and you get 3.7 tok/s. With MoE, only 3B are active and you get 120 tok/s. Same hardware, 32x faster.
Frequently Asked Questions
What is the difference between NVFP4 and GGUF?
NVFP4 is NVIDIA's native 4-bit number format designed specifically for Blackwell GPUs (like the one in the DGX Spark). It uses dedicated hardware in the GPU to compute directly on 4-bit values. GGUF is a general-purpose format used by llama.cpp that works across many GPU types. NVFP4 is faster on Blackwell hardware. GGUF is more portable across different hardware.
Why not link both machines for one big model?
We tested this. Linking via QSFP adds roughly 0.85 milliseconds of latency per neural network layer for synchronisation. With 40+ layers, that adds 30+ milliseconds per token. For our use case (interactive agents handling multiple concurrent tasks), two independent machines running in parallel outperform one linked machine.
Can I run this on a Mac instead?
The Qwen 3.6 model runs on Mac Studio with M4 Max and 128GB+ unified memory via llama.cpp. The Atlas engine specifically targets the DGX Spark's GB10 chip, so Mac users would use llama.cpp or vLLM instead. Step 3.5 Flash also runs on Mac via llama.cpp. Expect roughly 20-25 tok/s for Qwen and 15-20 tok/s for Step Flash on a high-end Mac.
How do you decide which model handles a task?
Simple tasks (tool calls, quick responses, routing) go to Qwen 3.6 on Spark 2 for speed. Complex tasks (multi-step reasoning, code analysis, research) go to Step 3.5 Flash on Spark 1 for quality. The orchestrator (OpenClaw in our case) makes the routing decision based on the task type.
Is 20.6 tok/s fast enough for reasoning tasks?
Yes, because reasoning tasks are not latency-sensitive in the same way interactive chat is. When an AI is thinking through a complex problem, the user expects to wait. A 20-second response that correctly solves a hard problem is better than a 2-second response that gets it wrong.