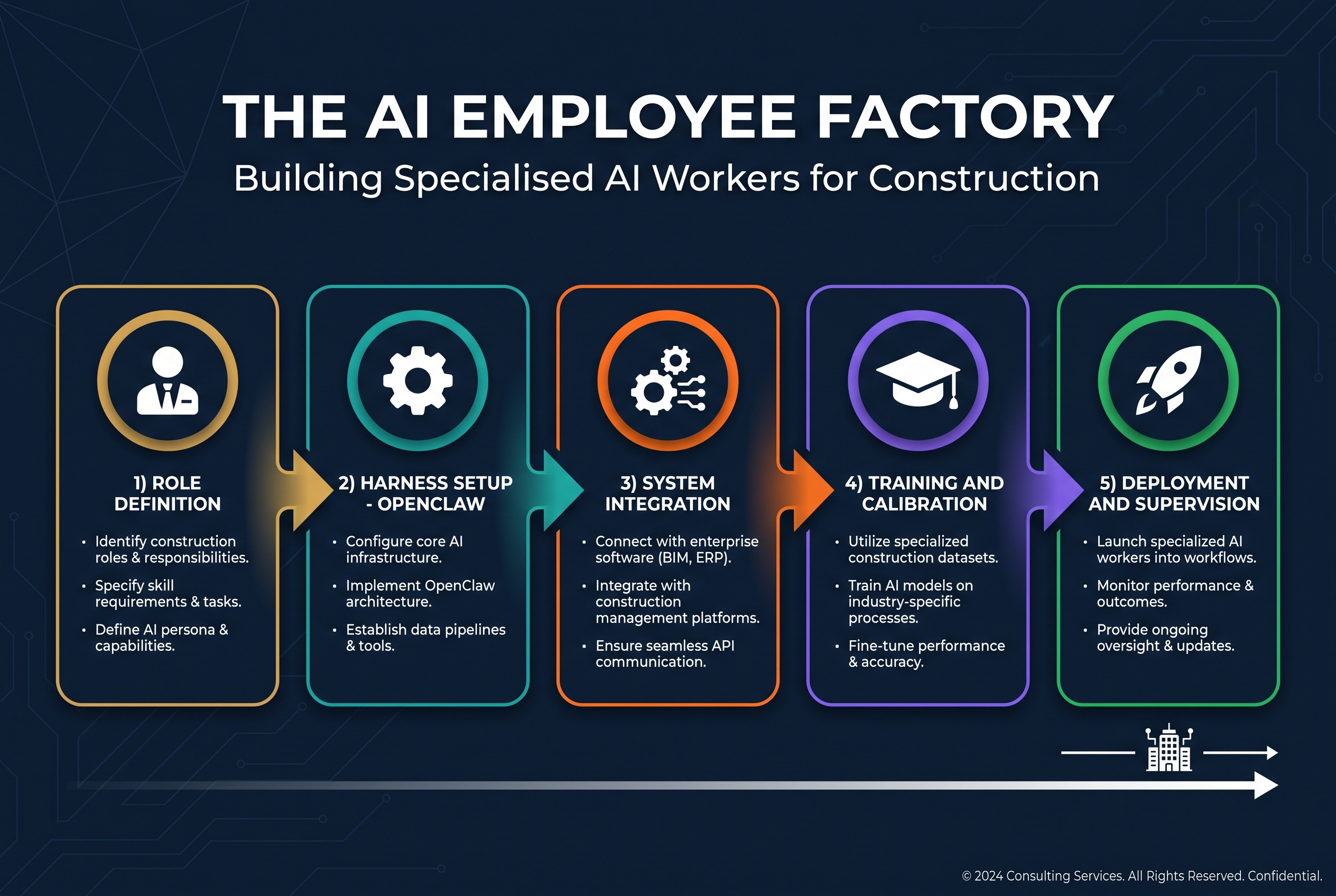
"I Just Ask My AI to Do It": What a Real AI Discovery Call Taught Me About Where Most Companies Actually Are
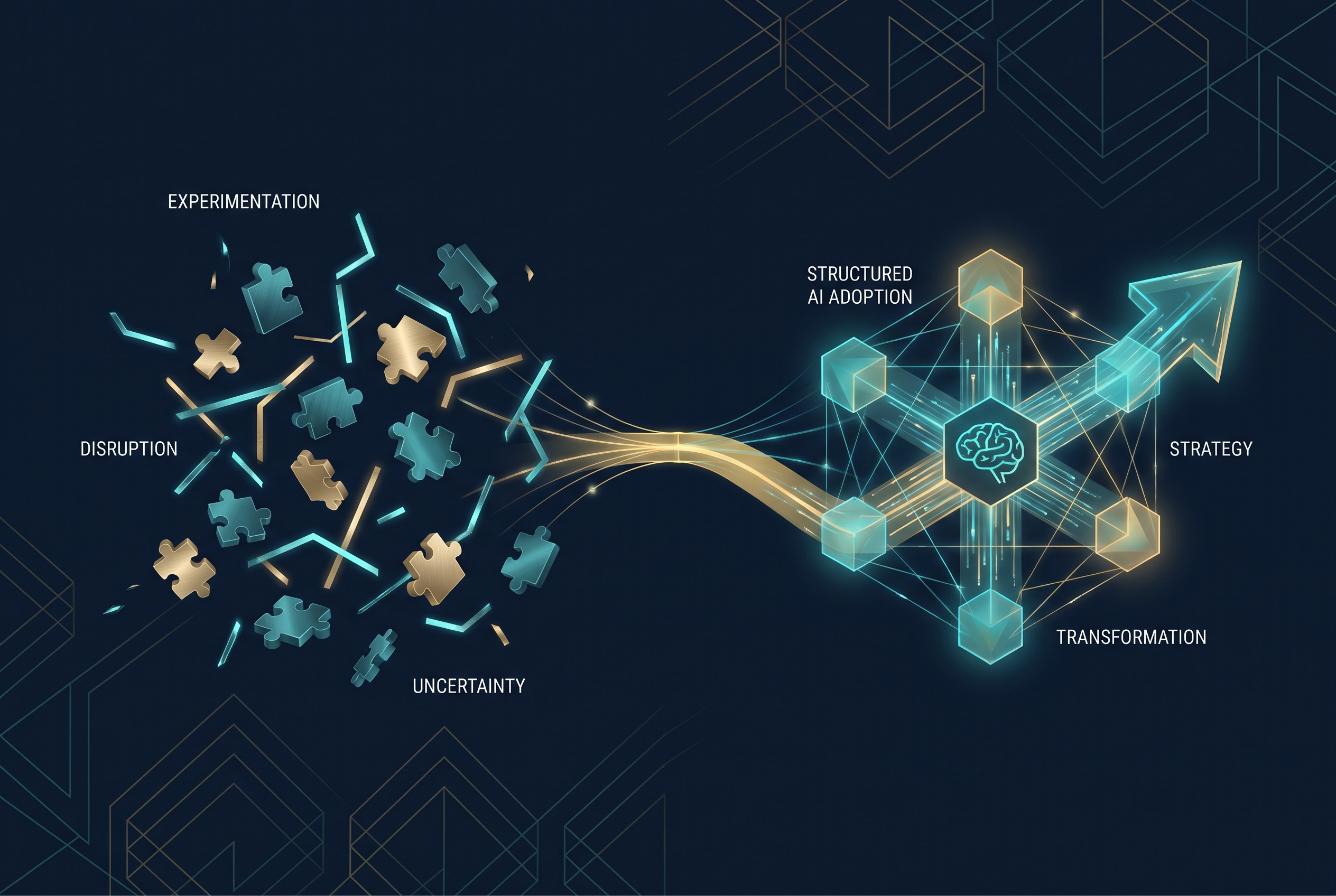
After sitting down with a Sydney construction firm to map out their AI strategy, I realised most companies are stuck between bottom-up experimentation and top-down ambition. Here's what a real discovery call revealed about where Australian businesses actually stand with AI adoption.
22 July 202611 min read
Read more