Last Updated: May 10, 2026
A single developer just did what billion-dollar infrastructure teams said was impossible. Salvatore Sanfilippo, the legendary creator of Redis, released ds4: a purpose-built inference engine that runs DeepSeek V4 Flash, a 284-billion parameter frontier model, locally on a MacBook with 128GB of RAM.
This is not a toy demo. This is a production-quality inference engine with an OpenAI-compatible API, 1-million token context, thinking mode, and integration with coding agents like Claude Code. And it runs on consumer hardware you can buy today.

What Is DeepSeek V4 Flash?
DeepSeek V4 Flash is a 284-billion parameter Mixture-of-Experts model released by DeepSeek in April 2026. It is the "Flash" variant of DeepSeek V4, optimised for fast inference while retaining frontier-level reasoning capability.
Key specifications:
- 284B total parameters, only 13B active per token (Mixture-of-Experts)
- 1-million token context window
- Hybrid Attention Architecture that reduces KV cache to 10% of previous generation size
- Thinking mode that produces reasoning chains proportional to problem complexity (often 1/5 the length of competing models)
- 72.1 tokens per second on DeepSeek's official API (reasoning mode, max effort)
- Open-weight model available on Hugging Face
The 13B active parameter count is what makes local inference feasible. The model has 284B parameters of knowledge stored across hundreds of expert modules, but only activates 13B per token. This means the computational cost per generation step is similar to a 13B dense model, while the knowledge depth rivals models 20x larger.
Community consensus from early testers: "NOTHING comes close at this size. Not Qwen 3.5-122B, not MiniMax 2.7. DeepSeek V4 Flash is SOTA that you can run locally under 128GB."
What Is ds4?
ds4 is a single-file C inference engine (ds4.c) written by Salvatore Sanfilippo specifically for DeepSeek V4 Flash on Apple Metal. It is intentionally narrow: not a generic GGUF runner, not a framework, not a wrapper around another runtime. One model, one hardware platform, maximum performance.
Why ds4 exists instead of using llama.cpp or vLLM:
Generic inference engines optimise for breadth (running many models). ds4 optimises for depth (running one model perfectly). By constraining the problem to a single model architecture, antirez could implement DeepSeek V4 Flash-specific optimisations that general engines cannot match.
Core innovations:
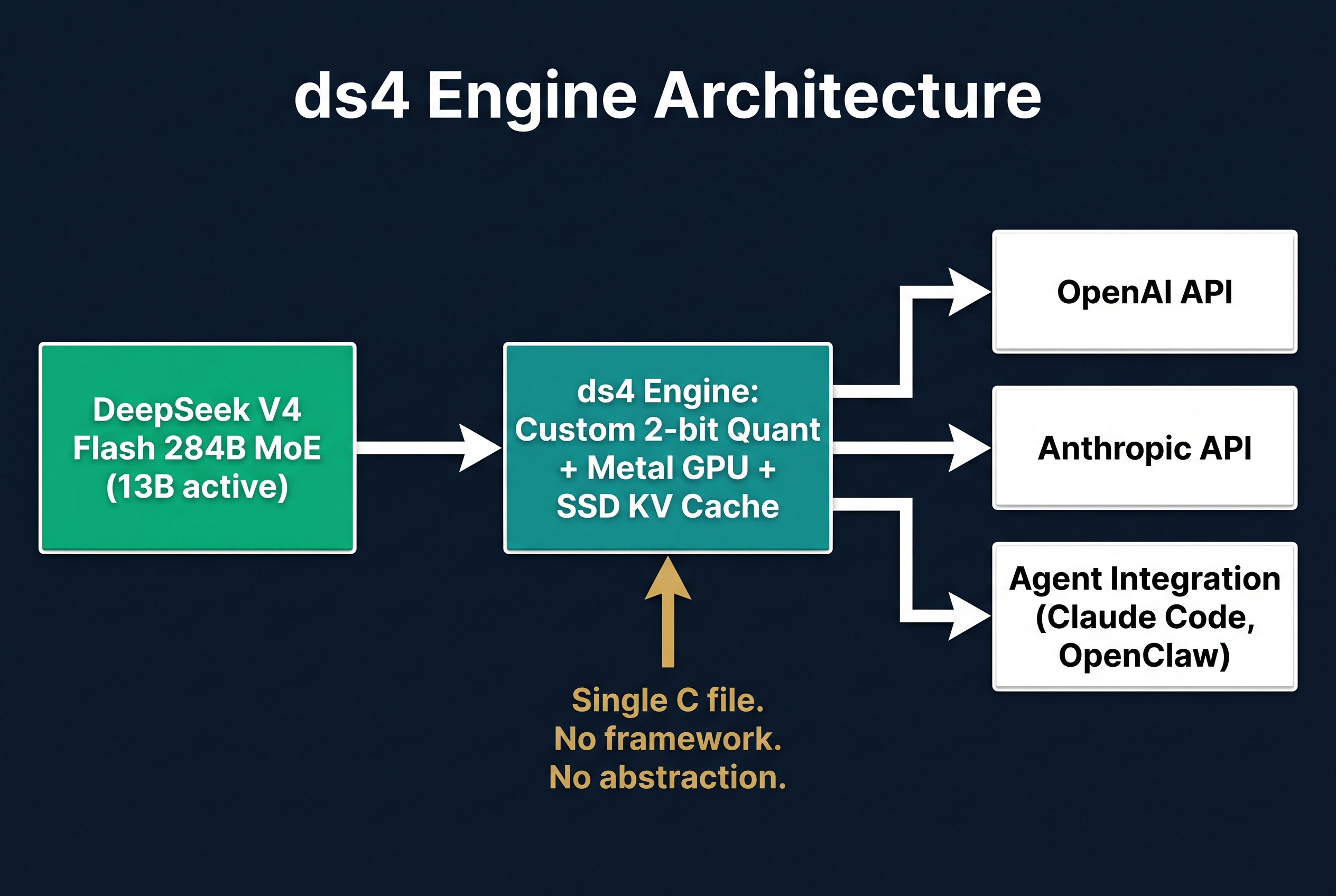
Custom 2-bit quantization. The GGUF files are not standard quantised formats. They use a specially crafted quantization mix validated against official DeepSeek logits at different context sizes. This is not Q2_K with quality loss. It is a purpose-built compression scheme that maintains accuracy while fitting the full 284B model into ~70GB of memory.
KV cache on SSD. This is the breakthrough. Traditional inference keeps the KV cache in RAM, which limits context length to whatever memory remains after model loading. DeepSeek V4's hybrid attention architecture compresses the KV cache to 10% of previous generation size. ds4 exploits this by treating the SSD as a first-class KV cache citizen. The result: 1-million token context on a MacBook, with KV cache persistence across restarts.
Native Metal execution. ds4 does not go through GGML or any abstraction layer. It is a direct Metal graph executor with DeepSeek V4 Flash-specific loading, prompt rendering, and state management. This removes overhead and enables optimisations that general-purpose engines cannot achieve.
Agent-ready API. ds4 exposes an OpenAI-compatible HTTP API and an Anthropic-compatible API out of the box. It has been tested with Claude Code, opencode, and Pi. This is not a research project. It is designed for production agent workflows.
How Does ds4 Perform on a 128GB MacBook?
The honest numbers from community benchmarks and antirez's own testing:
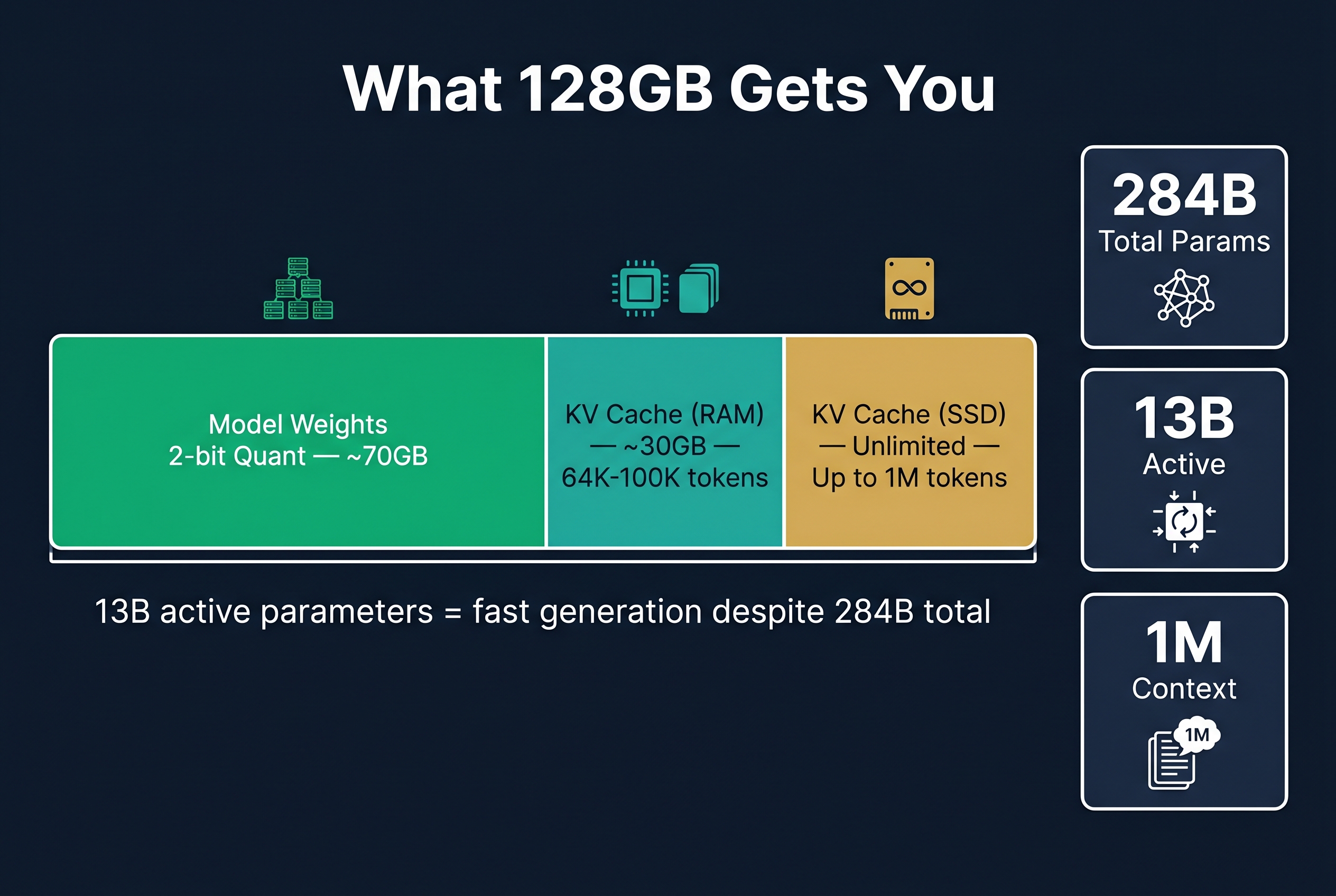
Memory budget on 128GB MacBook:
- Model weights (2-bit quantized): ~70GB
- Available for KV cache: ~30GB remaining in RAM
- Practical context before SSD KV cache: 64K-100K tokens
- Maximum context (with SSD KV cache): 1M tokens
- KV cache persists to disk, surviving restarts
Generation speed:
- With 13B active parameters, generation is fast for a 284B model
- Exact tok/s benchmarks vary by context length and batch size
- Significantly faster than running dense models of equivalent quality because MoE only activates 13B per token
Quality assessment:
- Community reports describe it as a "quasi-frontier model"
- 284B parameters of knowledge shows in edge-case queries (obscure topics, multilingual, specialised domains)
- Thinking mode is practical for daily use because reasoning chains are short and proportional to complexity
- Zero looping issues reported (a common problem with other local models)
Why This Matters for Australian Businesses
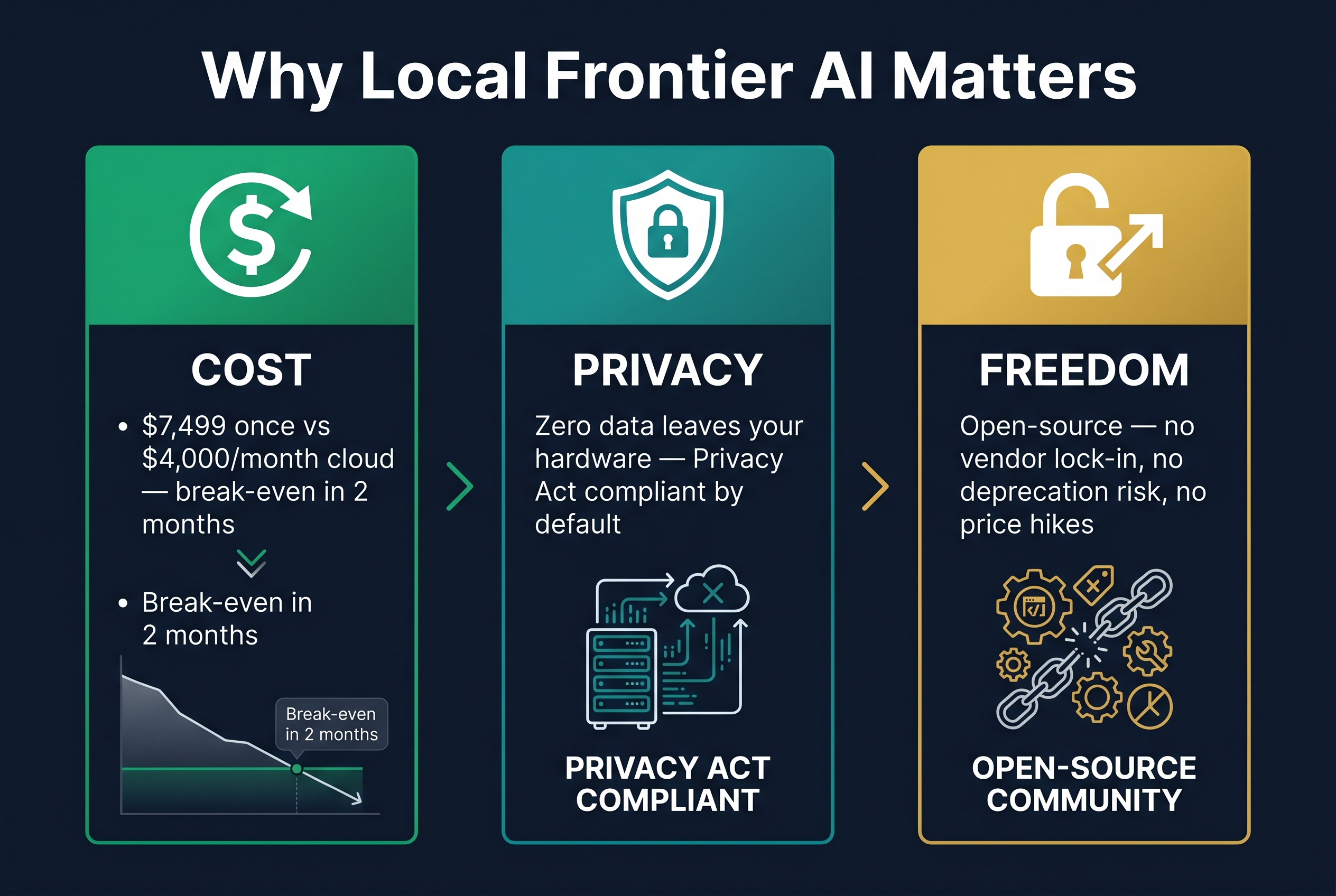
1. Cost elimination. Running DeepSeek V4 Flash locally on a MacBook eliminates per-token API costs entirely. A 128GB MacBook Studio costs approximately $7,499 AUD. That is a one-time hardware purchase that gives you unlimited frontier-level inference. Compare this to $2,000-$8,000 per month in cloud API costs for equivalent usage.
2. Data sovereignty. When you run AI locally, your data never leaves your hardware. No client data passes through US cloud servers. No third party processes your proprietary information. For businesses subject to the Australian Privacy Act (amendments effective December 2026), health data regulations, or government security requirements, this is the strongest possible compliance position.
3. Agent infrastructure. ds4 is designed for agents, not just chat. The OpenAI-compatible API means you can point your existing agent frameworks (OpenClaw, NemoClaw, Claude Code) at your local MacBook instead of OpenAI's servers. Your agents get frontier-level reasoning with zero marginal cost per request.
4. No vendor dependency. DeepSeek V4 Flash is open-weight. ds4 is open-source (MIT license). No one can deprecate the model, change pricing, or restrict your access. You own the entire stack.
ds4 vs Cloud APIs vs DGX Spark: Where Does Each Fit?
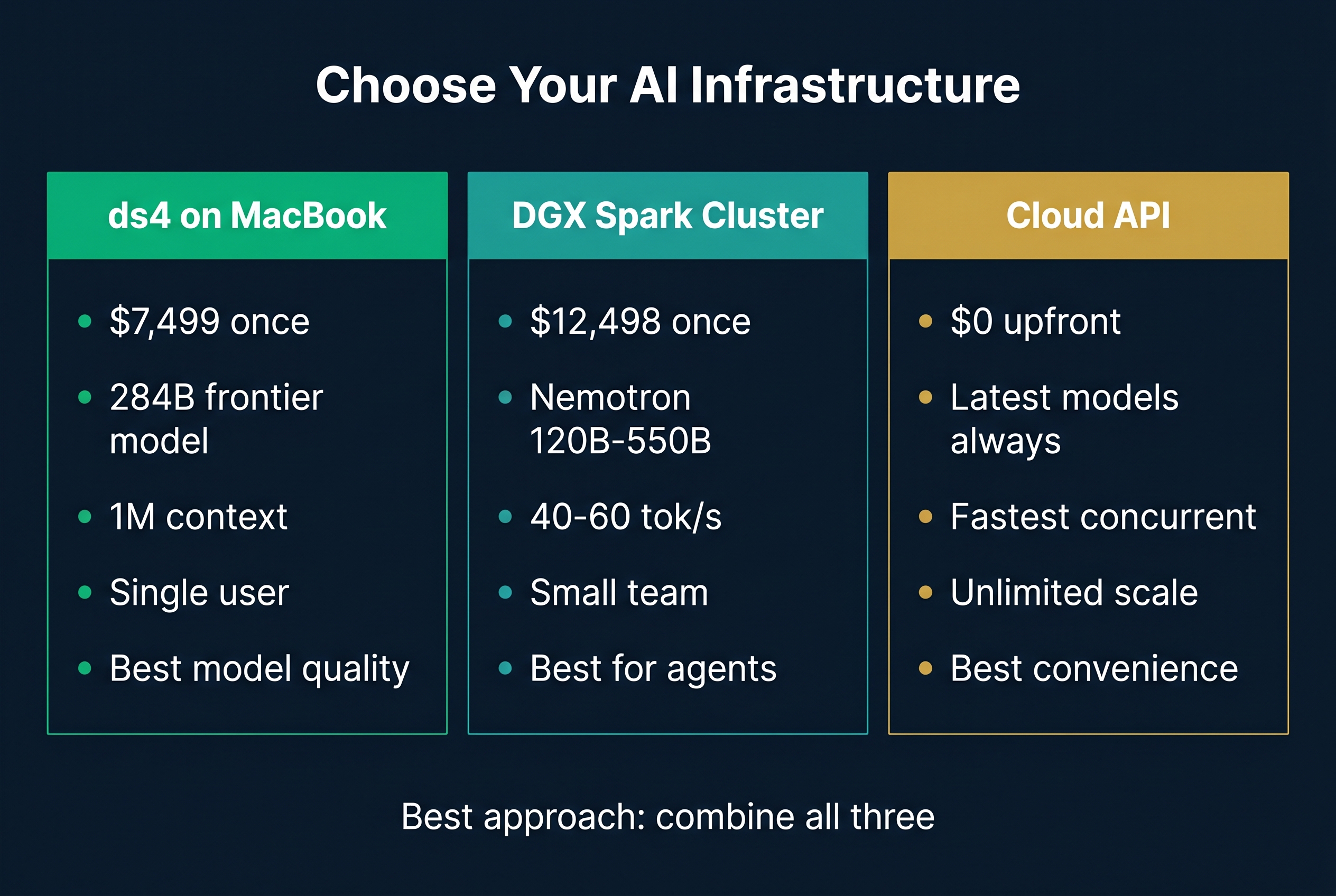
| Factor | ds4 on MacBook | Cloud API (GPT-5.4) | DGX Spark (Nemotron) |
|---|---|---|---|
| Upfront cost | $7,499 (Mac Studio) | $0 | $12,498 (2x Spark) |
| Ongoing cost | $0 (electricity only) | $2,000-8,000/month | $0 (electricity only) |
| Model quality | Frontier (284B MoE) | Frontier (GPT-5.4) | Near-frontier (120B-550B) |
| Speed | Moderate (13B active) | Fast (cloud hardware) | Fast (40-60 tok/s) |
| Context | 1M tokens | 128K-1M | 32K-128K |
| Data sovereignty | Full | None | Full |
| Agent support | Excellent | Excellent | Excellent |
| Scalability | Single user | Unlimited | Small team |
The right tool depends on your situation:
Choose ds4 on MacBook if: You are an individual consultant, developer, or small team that needs frontier AI for coding agents, research, and document processing. You want the best possible model quality at the lowest possible cost with full data sovereignty. This is the most capital-efficient path to frontier AI.
Choose DGX Spark if: You are running multiple agents simultaneously, need fast inference for real-time applications, want to serve a small team, or need to run multiple models in parallel (orchestrator + workers). The Spark gives you GPU acceleration, clustering, and the NVIDIA software stack.
Choose cloud APIs if: You have bursty workloads, need the absolute latest models on day one, or are serving many concurrent users. The cloud wins on convenience and scale, but loses on cost and data sovereignty over time.
The hybrid approach (best of all worlds): Run ds4 on a MacBook Studio for your personal coding agents and research. Run DGX Spark for your team's production agents. Use cloud APIs only when you need the newest model on release day. This gives you frontier quality everywhere, minimal ongoing cost, and full data control.
The Bigger Picture: Open Source Is Winning
The release of ds4 illustrates a fundamental shift in AI capability distribution.
Closed-source labs are spending tens of billions on massive GPU clusters to train and serve proprietary models. Meanwhile, individual developers like antirez are building inference engines that run those same quality levels on consumer hardware. DeepSeek releases frontier-class open weights. One person builds a custom engine. The result is indistinguishable from the trillion-dollar product for most practical use cases.
This pattern will accelerate. Each generation of open-weight models gets better. Each generation of hardware gets more capable. Each clever optimisation (SSD KV cache, compressed attention, custom quantisation) closes the gap further.
For businesses, the implication is clear: the cost of frontier AI intelligence is going to zero. The question is not whether you can afford to run frontier models locally. It is whether you can afford to keep paying per-token prices for something that will soon be essentially free.
Getting Started With ds4
If you have a MacBook with 128GB of unified memory (MacBook Pro M4 Max or Mac Studio M4 Ultra), you can run ds4 today:
- Clone the repository from github.com/antirez/ds4
- Download the specially crafted DeepSeek V4 Flash GGUF files (linked in the repo)
- Compile ds4 (single C file, Metal dependencies)
- Launch the server with the OpenAI-compatible API
- Point your agents at the local endpoint
The setup takes approximately 30 minutes for a developer comfortable with the terminal. For businesses that want help integrating ds4 into their agent workflows, Flowtivity provides deployment and architecture services.
The Bottom Line
Salvatore Sanfilippo, working alone with GPT 5.5 assistance, built an inference engine that runs a 284-billion parameter frontier model on a laptop. DeepSeek released the model weights for free. The combination delivers GPT-5-class reasoning at zero per-token cost with full data sovereignty.
This is not a future prediction. It is available today. The only question is whether your business starts using it now or keeps renting intelligence by the token.
About the author: AJ Awan is the founder of Flowtivity, an Australian AI consultancy specializing in workflow automation and AI agent deployment for growing businesses. With 9+ years of consulting experience including 6 years at EY, AJ helps companies integrate local AI infrastructure that eliminates per-token costs while meeting Australian compliance requirements.