
Last Updated: April 24, 2026
DeepSeek just dropped V4 today, and the AI pricing landscape just got turned on its head. Two models, a native 1M token context window, open-source weights, and pricing that makes every other frontier model look expensive. Here's the full breakdown of how it stacks up against GPT-5.5, Claude Opus 4.7, and GLM-5.1 on cost, benchmarks, and real-world value.
What Is DeepSeek V4?
DeepSeek V4 is the fourth-generation model family from the Hangzhou-based AI lab, released April 24, 2026. It ships in two variants: DeepSeek V4-Flash (284B total parameters, 13B active) and DeepSeek V4-Pro (1.6T total parameters, 49B active). Both are Mixture-of-Experts models with native 1M token context windows.
The key insight: only a fraction of parameters activate per token, which is how DeepSeek delivers frontier-level performance at a fraction of the cost. V4-Flash activates just 13B parameters per forward pass while maintaining competitive benchmarks with models that cost 10-36x more.
Both models are open-source on HuggingFace with live API access today. DeepSeek has also introduced a hybrid attention architecture (Compressed Sparse Attention + Heavily Compressed Attention) that makes the 1M context window actually usable without prohibitive memory costs.
How Much Does Each Model Cost? (April 2026 Pricing)
This is where DeepSeek V4 becomes impossible to ignore. All prices below are per million tokens.
DeepSeek V4-Flash costs $0.14 per million input tokens and $0.28 per million output tokens (cache miss). With cache hits, input drops to just $0.028 per million tokens. For context, that means processing 10 million tokens of code costs $1.40.
DeepSeek V4-Pro costs $1.74 per million input tokens and $3.48 per million output tokens. That's the flagship model with 1.6T parameters and 49B active, and it's still cheaper than most competitors.
GPT-5.5 (OpenAI) costs $5.00 per million input tokens and $30.00 per million output tokens. That's 36x more expensive than V4-Flash on input and 107x more on output.
Claude Opus 4.7 (Anthropic) costs $5.00 per million input tokens and $25.00 per million output tokens. Anthropic released Opus 4.7 on April 16, 2026, keeping the same pricing as Opus 4.6.
Claude Opus 4.6 costs $5.00 per million input tokens and $25.00 per million output tokens. Same price, older model.
Gemini 3.1 Flash (Google) costs $0.50 per million input tokens and $3.00 per million output tokens on the standard tier. With batch processing, it drops to $0.25/$1.50. It supports a 1M token context window, making it the second-cheapest 1M-context option after DeepSeek V4-Flash.
GLM-5.1 (Zhipu AI / Z.AI) costs $1.05 per million input tokens and $3.50 per million output tokens on the standard tier, or $1.40/$4.40 on some providers. GLM-5.1 is the cheapest non-DeepSeek option in this comparison.
The Cost Table
| Model | Input ($/MTok) | Output ($/MTok) | Context Window | Open Source? |
|---|---|---|---|---|
| DeepSeek V4-Flash | $0.14 | $0.28 | 1M | Yes |
| Gemini 3.1 Flash | $0.50 | $3.00 | 1M | No |
| DeepSeek V4-Pro | $1.74 | $3.48 | 1M | Yes |
| GLM-5.1 | $1.05 | $3.50 | 262K | Yes |
| GPT-5.5 | $5.00 | $30.00 | 256K | No |
| Claude Opus 4.7 | $5.00 | $25.00 | 200K | No |
| Claude Opus 4.6 | $5.00 | $25.00 | 200K | No |

Real-World Cost Example: Processing a Large Codebase
Let's say you're analyzing a monorepo with 5 million tokens of code (roughly 50,000 lines across hundreds of files), and the model generates 500K tokens of analysis and refactored code.
| Model | Input Cost | Output Cost | Total |
|---|---|---|---|
| DeepSeek V4-Flash | $0.70 | $0.14 | $0.84 |
| Gemini 3.1 Flash | $2.50 | $1.50 | $4.00 |
| DeepSeek V4-Pro | $8.70 | $1.74 | $10.44 |
| GLM-5.1 | $5.25 | $1.75 | $7.00 |
| GPT-5.5 | $25.00 | $15.00 | $40.00 |
| Claude Opus 4.7 | $25.00 | $12.50 | $37.50 |
DeepSeek V4-Flash handles the entire job for under a dollar. GPT-5.5 charges $40 for the same work. That's a 48x price difference.
How Do They Compare on Coding Benchmarks?
Benchmarks don't tell the whole story, but they give us a starting point. Here's how the models stack up on the most respected coding and reasoning benchmarks as of April 2026.
SWE-bench Verified (Resolving Real GitHub Issues)
This benchmark tests whether a model can actually fix real bugs from open-source projects. It's the gold standard for coding agents.
Claude Opus 4.6 leads at 80.8% SWE-bench Verified, with DeepSeek V4-Pro close behind at approximately 80.6%. GLM-5.1 scores around 77.8%. The open-source Qwen 3.6-27B (which runs on a consumer RTX 4090) achieves an impressive 77.2%, beating models 15x its size.
SWE-bench Pro (Harder, Post-Cutoff Issues)
SWE-bench Pro uses issues filed after training cutoff, reducing data contamination. GLM-5.1 leads this benchmark at 58.4%, followed closely by Kimi K2.6 at 58.6% and DeepSeek V4-Pro in the same range. This tests genuine generalization rather than memorized solutions.
Terminal-Bench 2.0 (Live Terminal Tasks)
Terminal-Bench 2.0 evaluates models in real terminal environments, requiring them to read output, handle errors, and iterate. This is closer to what production coding agents actually do.
DeepSeek V4-Pro leads at 67.9%, followed by Claude Opus 4.6 at 65.4%, and Qwen 3.6 Plus at 61.6%. V4-Pro's strength here suggests it handles multi-step tool-calling workflows better than competitors.
Codeforces Rating
DeepSeek V4-Pro achieves a Codeforces rating of 3,206, ranking 23rd among human competitors. This is competitive programming at the highest level, testing algorithmic thinking under time pressure. No other model in this comparison publishes a comparable Codeforces rating.
LiveCodeBench
DeepSeek V4-Pro scores 93.5% on LiveCodeBench, compared to Claude's 88.8%. This benchmark tests code generation across multiple languages and difficulty levels.
The Benchmark Summary
| Model | SWE-bench Verified | Terminal-Bench 2.0 | LiveCodeBench | Codeforces |
|---|---|---|---|---|
| DeepSeek V4-Pro | ~80.6% | 67.9% | 93.5% | 3,206 |
| Claude Opus 4.7 | ~80.8% | ~65.4% | ~88.8% | N/A |
| Claude Opus 4.6 | 80.8% | 65.4% | 88.8% | N/A |
| Gemini 3.1 Flash | ~72-74% (est) | ~55% (est) | ~85% (est) | N/A |
| GPT-5.5 | ~79-80% | ~63% | ~90% | N/A |
| GLM-5.1 | ~77.8% | 55%+ | ~85% | N/A |
| DeepSeek V4-Flash | ~76-78% (est) | ~60% (est) | ~88% (est) | N/A |
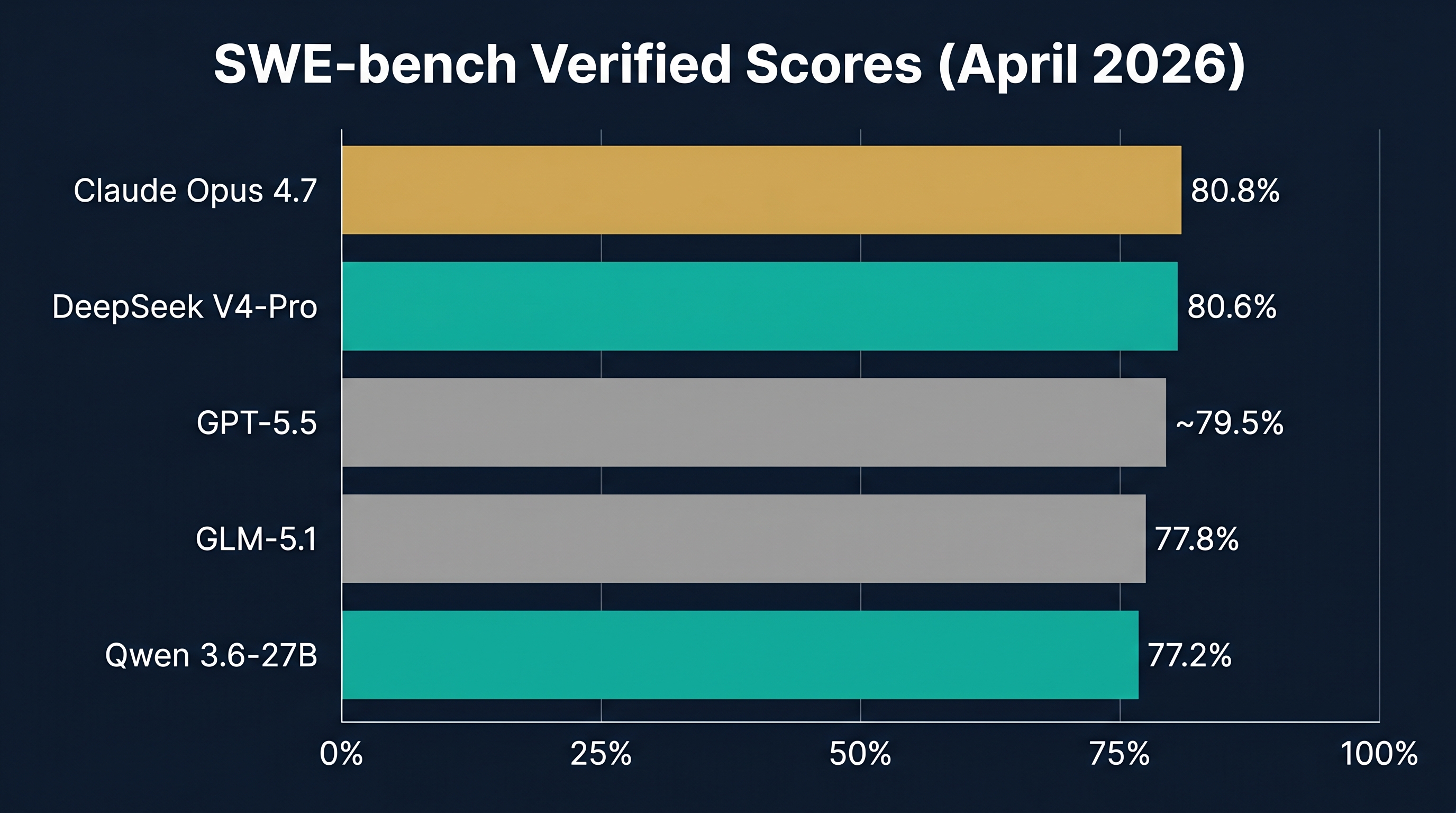
Key takeaway: DeepSeek V4-Pro trades blows with Claude Opus 4.7 on coding benchmarks, often winning on terminal tasks and competitive programming. V4-Flash is slightly behind but still competitive with models costing 18-36x more.
What About the 1M Context Window?
This is DeepSeek V4's biggest technical differentiator. While other models cap at 200K-262K tokens, V4 natively supports 1M tokens with architectural innovations that make it affordable.
The hybrid CSA (Compressed Sparse Attention) and HCA (Heavily Compressed Attention) architecture means V4-Pro uses only 27% of the FLOPs and 10% of the KV cache size compared to DeepSeek V3 when processing at 1M tokens. V4-Flash pushes that to 10% of FLOPs and 7% of cache.
What 1M tokens actually means in practice:
- ~800,000 words of text (about 8 full-length novels)
- An entire monorepo with thousands of files
- Full codebase + documentation + all pull requests in a single context
- Complete legal contracts, medical records, or financial reports without chunking
For businesses working with large documents or codebases, this eliminates the complexity of retrieval-augmented generation (RAG) pipelines and chunking strategies. You just load everything into context.
Can You Self-Host DeepSeek V4?
Yes, both models are open-source on HuggingFace. But there's a catch.
DeepSeek V4-Flash (284B total parameters): At 4-bit quantization, you need approximately 142GB of VRAM. That requires a minimum of 4x RTX 4090 GPUs (96GB total, plus system RAM offloading) or 2x A100 80GB. A realistic self-hosted setup would cost around $9,600 AUD for a 4x RTX 4090 rig.
DeepSeek V4-Pro (1.6T total parameters): Datacenter only. You'd need 8x H100 GPUs minimum. That's enterprise infrastructure territory, well beyond consumer self-hosting.
For Australian businesses wanting data sovereignty (keeping data onshore), the most practical approach is self-hosting a smaller model like Qwen 3.6-27B on a local RTX 4090 for everyday tasks, and using the DeepSeek V4 API for complex jobs requiring the 1M context window.
What Does This Mean for Australian Businesses?
The price gap between DeepSeek V4 and Western alternatives is staggering. For a business processing 100 million tokens per month (a heavy coding workload), here's the monthly bill:
| Model | Monthly Cost (100M tokens) |
|---|---|
| DeepSeek V4-Flash | ~$21 |
| Gemini 3.1 Flash | ~$65 |
| DeepSeek V4-Pro | ~$261 |
| GLM-5.1 | ~$175 |
| Claude Opus 4.7 | ~$1,500 |
| GPT-5.5 | ~$1,750 |
A business currently spending $1,500/month on Claude Opus could switch to DeepSeek V4-Flash and save $1,479/month while getting the same or better coding performance and a 5x larger context window. Even Gemini 3.1 Flash at $65/month represents a 96% saving. That's an annual saving of nearly $18,000 on DeepSeek or $17,220 on Gemini.
For businesses in regulated industries like healthcare, legal, and construction, the open-source nature of DeepSeek V4 also means you can eventually self-host for complete data sovereignty, something impossible with GPT-5.5 or Claude.
DeepSeek V4 vs GLM-5.1: Which Chinese AI Model Should You Use?
Both DeepSeek V4 and GLM-5.1 are Chinese-developed, open-source models with aggressive pricing. Here's how to choose between them.
Choose DeepSeek V4-Flash if you need the 1M context window, want the absolute cheapest per-token pricing ($0.14/MTok input), or are running large-scale batch processing. It's the value play.
Choose GLM-5.1 if you need the strongest SWE-bench Pro score (58.4%), do a lot of front-end web development (Code Arena Elo 1,530), or need a slightly smaller deployment footprint (754B total vs 284B for V4-Flash).
Choose DeepSeek V4-Pro if you want frontier-level performance across the board (80.6% SWE-bench, 67.9% Terminal-Bench, 3,206 Codeforces) at roughly one-third the price of Claude or GPT. It's the best open-source model in the world right now for pure coding performance.
How to Get Started with DeepSeek V4
DeepSeek V4 is available today through three channels:
1. Free Chat: Visit chat.deepseek.com and select V4-Flash or V4-Pro from the model dropdown. No API key needed.
2. API Access: Sign up at platform.deepseek.com, get an API key, and use the OpenAI-compatible endpoint at api.deepseek.com. The API supports both OpenAI ChatCompletions format and Anthropic format.
3. Self-Host: Download weights from HuggingFace (deepseek-ai collection). You'll need significant GPU resources — see the self-hosting section above for hardware requirements.
For Australian businesses integrating AI into workflows, the API is the fastest path. It works as a drop-in replacement for OpenAI or Anthropic APIs in most applications, including agent frameworks like OpenClaw, LangChain, and CrewAI.
The Bottom Line
DeepSeek V4 changes the economics of AI. V4-Flash delivers coding performance competitive with models that cost 18-36x more. V4-Pro matches or beats Claude Opus 4.7 on most coding benchmarks at one-third the price. The 1M context window eliminates the need for complex RAG pipelines.
For businesses spending more than $500/month on AI APIs, DeepSeek V4 represents potential savings of 70-95%. And because it's open-source, you always have the self-hosting option for data-sensitive workloads.
The AI pricing war is real, and DeepSeek just fired the biggest shot.
Frequently Asked Questions
Is DeepSeek V4 better than Claude Opus 4.7?
DeepSeek V4-Pro trades blows with Claude Opus 4.7. V4-Pro wins on Terminal-Bench 2.0 (67.9% vs 65.4%), LiveCodeBench (93.5% vs 88.8%), and Codeforces rating. Claude holds a marginal lead on SWE-bench Verified (80.8% vs ~80.6%). The practical difference is small, but DeepSeek costs 3-36x less.
How much does DeepSeek V4 cost compared to GPT-5.5?
DeepSeek V4-Flash costs $0.14 per million input tokens versus GPT-5.5's $5.00, making it 36x cheaper on input. On output, V4-Flash costs $0.28 versus GPT-5.5's $30.00, a 107x difference. For most workloads, DeepSeek V4 delivers 90-95% of the quality at 3-5% of the cost.
Can I run DeepSeek V4 locally?
V4-Flash (284B total params) requires approximately 142GB at 4-bit quantization, needing 4x RTX 4090 or 2x A100 GPUs. V4-Pro (1.6T total params) requires datacenter infrastructure (8x H100). For local self-hosting on a single consumer GPU, consider Qwen 3.6-27B instead.
What is the context window of DeepSeek V4?
Both DeepSeek V4-Flash and V4-Pro support a native 1M token context window (approximately 800,000 words). This is 5x larger than Claude's 200K and nearly 4x larger than GLM-5.1's 262K.
Is DeepSeek V4 open source?
Yes, both V4-Flash and V4-Pro are released as open-source models on HuggingFace. You can download the weights, run them locally, and fine-tune them. The API is also available with OpenAI-compatible and Anthropic-compatible formats.


