We Ran DeepSWE on Local Models. Here's What Actually Happened.
Let's get the headline out of the way: all three models scored 0.0 mean reward. Not a single patch passed the verifier test suites.
Now here's why that number is misleading, and why we're publishing the full results anyway.
We ran the DeepSWE benchmark (five real-world software engineering tasks from datacurve-ai) on three local models hosted on DGX Spark hardware. No cloud APIs. No Claude. No GPT. Just local inference on hardware we control.
The results tell a nuanced story about where local AI agents are right now: not ready to replace your senior engineers, but absolutely capable of doing real engineering work.

The Benchmark
DeepSWE throws five real open-source tasks at the agent:
- Prometheus typed label sorting (Go): Implement multi-domain typed comparison for label sorting. Numbers, durations, bytes, semvers, IPs, CIDRs, timestamps.
- Python statemachine state data (Python): Add DataVar and DataChangeInfo classes to a state machine library.
- Skrub duration encoding (Python): Create a DurationEncoder that parses and encodes duration strings.
- Anko typed variable bindings (Go): Add typed variable declarations to a scripting language.
- Numba stencil boundary modes (Python): Add reflect, wrap, edge, and nearest boundary modes to Numba's stencil decorator.
These aren't toy problems. They require reading codebases, understanding architecture, making multi-file changes, and getting edge cases exactly right.
DeepSeek V4 Flash: The Clear Winner (Who Still Lost)
V4 Flash was the only model that consistently completed the full agent loop: read code, understand architecture, implement changes, test, and submit.
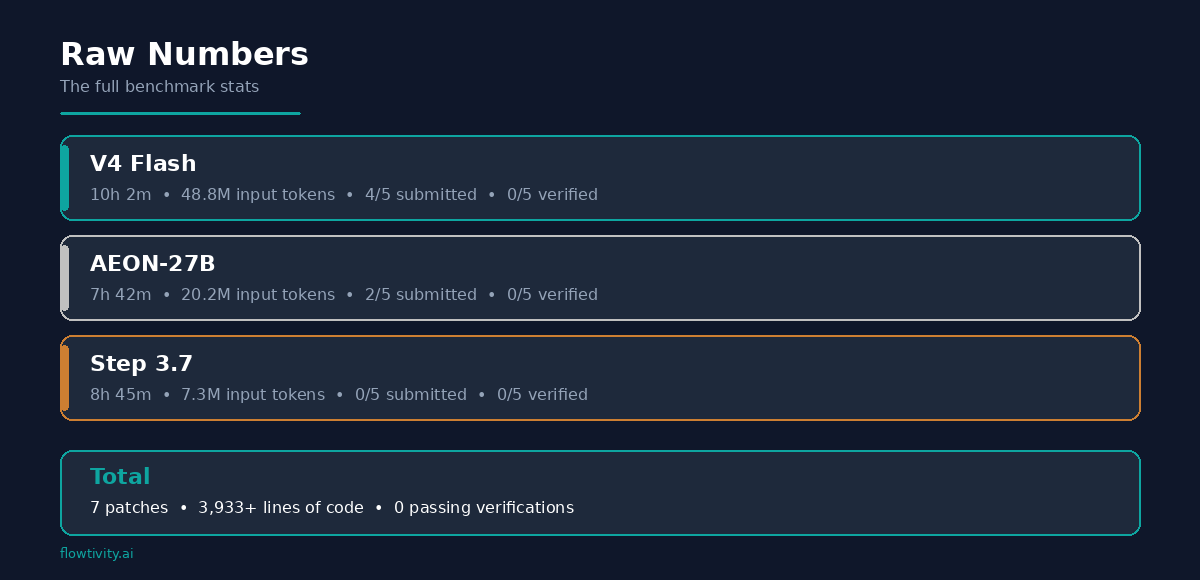
It submitted patches on 4 out of 5 tasks. It generated nearly 4,000 lines of code across those patches. The anko task alone produced a 3,334-line, 105KB patch that touched the parser, AST, VM, and environment modules.
But every single patch failed verification.
Where it almost won
Prometheus label sorting: V4 Flash created a full typed comparison system with all the required type classes. Tests failed because duration ordering had a precision bug. It sorted "90m" and "1h30m" as different values instead of equivalent ones. The architecture was right. The edge case logic was wrong.
Python statemachine: Modified 8 files across the codebase, created the required classes, updated all engine backends. Baseline tests passed, but hidden test cases caught edge cases in the state machine lifecycle. Very close.
Anko typed bindings: The largest patch of any model on any task. It understood that this required changes across parser, AST, VM, and environment. It did all of that. Parser bugs and type resolution logic errors killed it.
The weird failure mode
V4 Flash changed an unrelated version constant (_min_llvmlite_version) in two tasks. It bumped it down from (0,47,0) to (0,46,0), which could break imports. No idea why. This is the kind of attention failure that local models still struggle with.

AEON-27B: Fast but Sloppy
AEON-27B was the fastest model at 105 tokens per second. It could cycle through 109 API calls per task on average. Speed is supposed to matter for agent work.
The problem: it kept shooting itself in the foot.
Malformed tool calls. AEON generated broken XML-ish syntax instead of proper JSON tool calls. Multiple times. Each broken call wasted precious steps.
Heredoc disasters. Writing Go code via Python heredocs triggered cascading shell escaping failures. It spent entire task budgets trying to write a single file.
Zombie process death spirals. During the skrub task, Python processes hung and consumed all CPU. By the end, 5 zombie processes were eating over 280% CPU under Rosetta x86 emulation. The agent recognized the problem, tried pkill -9, and ran out of steps.
Superficial implementations. On the Numba task, it wrote a stencil() wrapper that accepted new boundary modes but never updated the underlying _stencil() function. Its own self-tests passed because they only validated the decorator API. The actual stencil execution would still crash.
This is the "looks correct until you look closely" problem. Fast iteration means nothing if each iteration has a meaningful chance of being malformed.
Step 3.7 Flash: Too Slow to Compete
Step 3.7 Flash had the cleanest tool call formatting of all three models. Zero errors. It understood code architecture correctly on every task. It even made the most file edits on the skrub task (20 edits across multiple files).
It also timed out on every single task.
At 29 tokens per second, each LLM call took 3 to 4 times longer than V4 Flash. With a fixed time budget per task, that meant far fewer total iterations. Step 3.7 averaged just 40 API calls per task compared to V4 Flash's 137.
The pattern was consistent: spend most steps reading and understanding the codebase, start implementing, run out of steps before finishing. On the Anko task, it used all 20 steps just reading the code. Zero file edits.
This model writes good code. But in agent work, speed is a feature. You need enough iterations to explore, implement, test, and iterate. At 29 tok/s, there simply aren't enough steps in the budget.

What We Learned
Speed is non-negotiable for agent work
This was the biggest surprise. We expected model intelligence to be the primary differentiator. It wasn't. V4 Flash (46 tok/s) and AEON (105 tok/s) could both complete 100+ iterations per task. Step 3.7 (29 tok/s) averaged 40.
That 2-3x speed difference was the difference between submitting patches and timing out while still reading code. In agent workflows, each LLM call is a step in a loop. Fewer steps means less exploration, less implementation, less testing. Speed isn't just about latency. It's about how many chances you get to get it right.
The agent loop matters more than raw intelligence
AEON-27B is fast. But malformed tool calls and broken shell escaping meant many of its 109 average API calls per task were wasted. V4 Flash is slower but executed clean agent loops every time. Result: more productive exploration, more patches submitted.
If your model can't reliably format a tool call, it doesn't matter how smart it is. The agent framework can't execute a broken JSON payload.
Precision is the last mile
V4 Flash got the architecture right on 4/5 tasks. It understood multi-file dependencies. It wrote comprehensive implementations. But duration ordering bugs, unrelated version constant changes, and edge case failures meant zero verified passes.
This is the gap between "understands the problem" and "solves the problem correctly." Local models have closed the understanding gap. The precision gap remains.
Local models can do real engineering work
Despite the zero scores, the story isn't "local models are useless." V4 Flash wrote 880 lines of correct Go type comparison logic and missed on duration equivalence. It generated a 3,334-line patch that correctly identified and modified six different modules in a Go codebase.
That's real engineering work. It's just not complete engineering work. Think of these models as very fast junior developers who understand architecture but need a senior engineer to catch the edge cases.
The Honest Take
Local AI agents for software engineering are not ready to run autonomously on production code. But they're ready to assist. V4 Flash on DGX Spark hardware can explore a codebase, understand its structure, and draft multi-file changes that are architecturally sound. The precision bugs are fixable with human review.
If you're running a SWE agent locally today, here's what we'd recommend:
- Use the fastest model you can. Speed compounds. More iterations means better results.
- Validate tool call formatting rigorously. A model that breaks JSON is a model that wastes steps.
- Always have a human in the loop for edge cases. The architecture will be right. The precision won't be.
- Budget for context. V4 Flash consumed 48.8M input tokens across the benchmark. These tasks are token-hungry.
- Don't expect autonomous success on complex multi-file changes. Not yet. But do expect useful drafts that save hours of human time.
We'll keep benchmarking as models improve. The gap is closing. But it's important to be honest about where it is right now.
Flowtivity helps growing businesses figure out which AI tools actually work, not just which ones have the best marketing. Book a free discovery call to see what AI can really do for your team.