NVIDIA Polar: How to Train AI Agents Without Changing Their Code
Last Updated: May 28, 2026
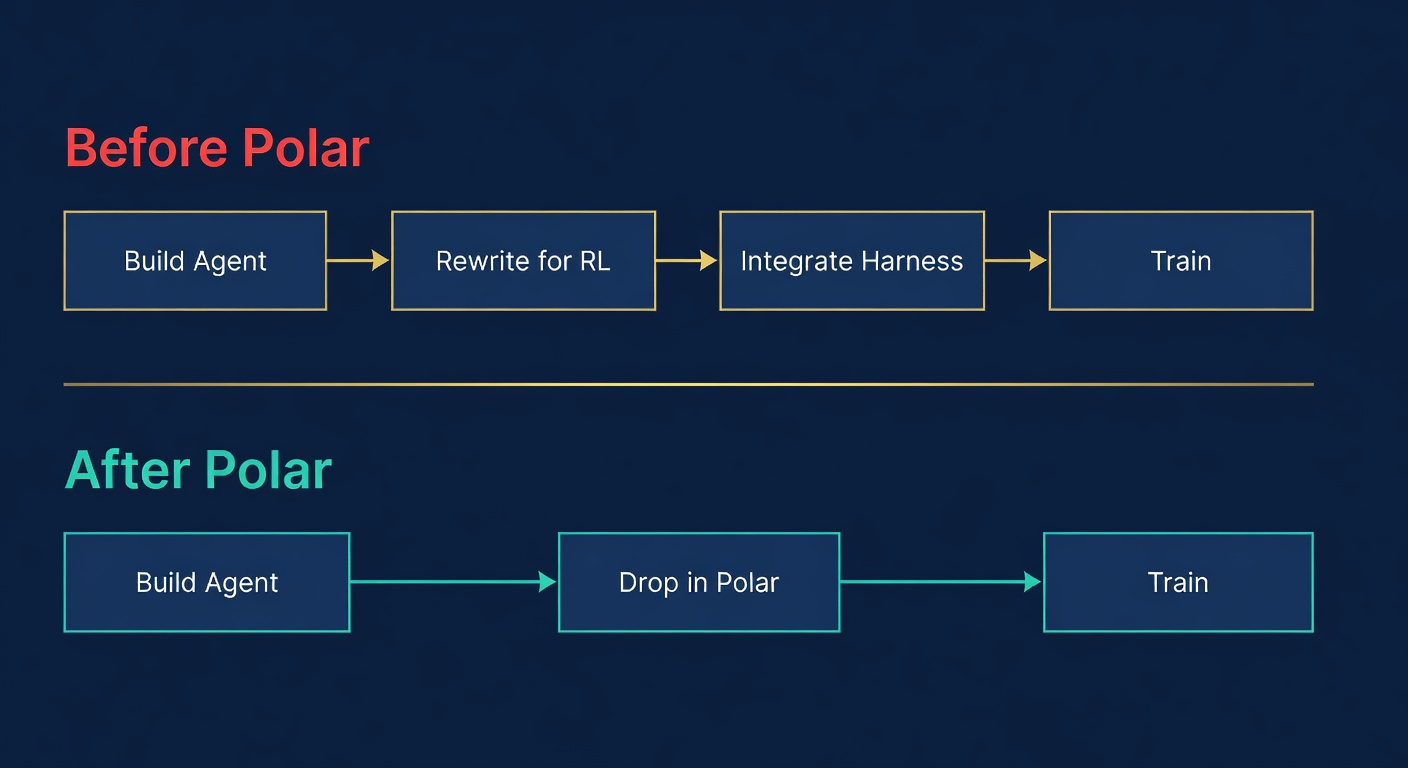
NVIDIA just dropped something that should make every AI builder sit up and pay attention. It's called Polar: a framework that lets you train AI agents with reinforcement learning without touching their code. Not "with minimal changes." Not "after some integration work." Without changing a single line.
If you've ever tried to apply RL to an existing agent, whether it's Claude Code, Codex CLI, or a custom workflow, you know the pain. You basically have to rip it apart and rebuild it for training. Polar makes that problem disappear.
Here's why it matters, what the numbers say, and what it means for businesses building with AI agents.
Why Has Training AI Agents Been So Difficult?
Training an AI agent with reinforcement learning should be straightforward in theory. The agent tries something, gets a reward signal, and learns to do better next time. Simple concept. In practice? It's a nightmare.
The problem is the harness: the orchestration layer that manages tool calls, context windows, multi-step reasoning, and API interactions. Every agent has one. Claude Code has one. Codex CLI has one. Your custom LangChain pipeline has one. And they're all different.
Why harnesses block RL training:
- No gradient access. Most harnesses call LLM APIs as black boxes. You can't backpropagate through OpenAI's servers.
- Token-level data is hidden. RL algorithms like GRPO need log probabilities and sampled tokens. Harnesses don't capture these.
- Session fragmentation. A single agent task might involve dozens of API calls. Stitching these into coherent training trajectories requires deep integration.
- Closed-source tools. You can't modify Claude Code or Codex CLI. Their harnesses are opaque.
So teams have been forced into an impossible choice: build custom training infrastructure for every agent, or skip RL entirely and hope prompting is enough.
That's the gap Polar fills.
Quick answer: Training AI agents with RL has been difficult because the orchestration layer (the "harness") sits between the agent and the LLM, hiding the token-level data that RL algorithms need. You'd have to rewrite the harness to capture this data, which is impossible for closed-source tools like Claude Code.
How Does Polar Solve the Harness Integration Problem?
Polar's insight is elegantly simple: instead of modifying the harness, put a proxy between the harness and the inference server.
Think of it like a network tap. The harness keeps making its API calls exactly as before. But those calls now pass through Polar's gateway, which records everything: prompts, sampled tokens, log probabilities, responses. Then Polar reconstructs these recordings into trainer-ready trajectories.
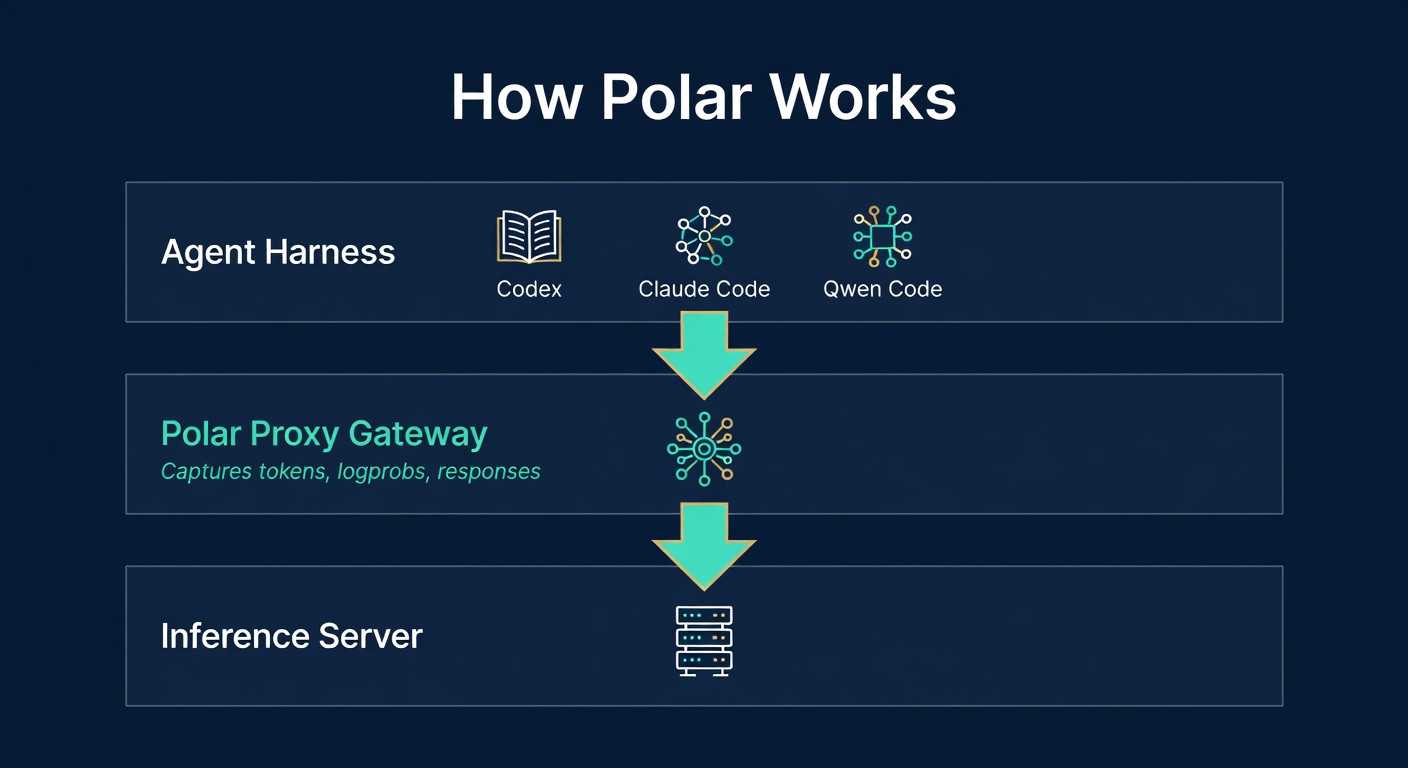
The architecture has three layers:
- Rollout server. The central coordinator that manages training runs and distributes work.
- Gateway nodes. The proxies that sit at the LLM API boundary, capturing token-level interactions transparently.
- Worker pools. Asynchronous pools (INIT → READY → RUNNING → POSTRUN) that handle rollout generation at scale.
The key innovation is that the harness is treated as a complete black box. Polar doesn't care what language it's written in, what framework it uses, or whether you have access to its source code. It only needs to see the API traffic.
This works with:
- Anthropic-style APIs
- OpenAI Chat and Responses APIs
- Google-style APIs
- Any LLM provider that uses standard API patterns
And because the rollout infrastructure is decoupled from training, you can scale them independently. Run 100 parallel rollouts on one cluster while your GPU training box does its thing elsewhere.
Quick answer: Polar places a transparent proxy at the LLM API boundary. The agent harness makes its normal API calls, but Polar's gateway captures every token, log probability, and response. These are then reconstructed into training trajectories, with no code changes needed in the harness itself.
What Results Does Polar Actually Achieve?
This is where it gets interesting. NVIDIA tested Polar on SWE-Bench Verified, which is the standard benchmark for evaluating AI agents on real software engineering tasks. They used GRPO (Group Relative Policy Optimization) as the RL algorithm.
The base model was Qwen3.5-4B, a 4-billion parameter model. That's small by today's standards. Here's what happened:
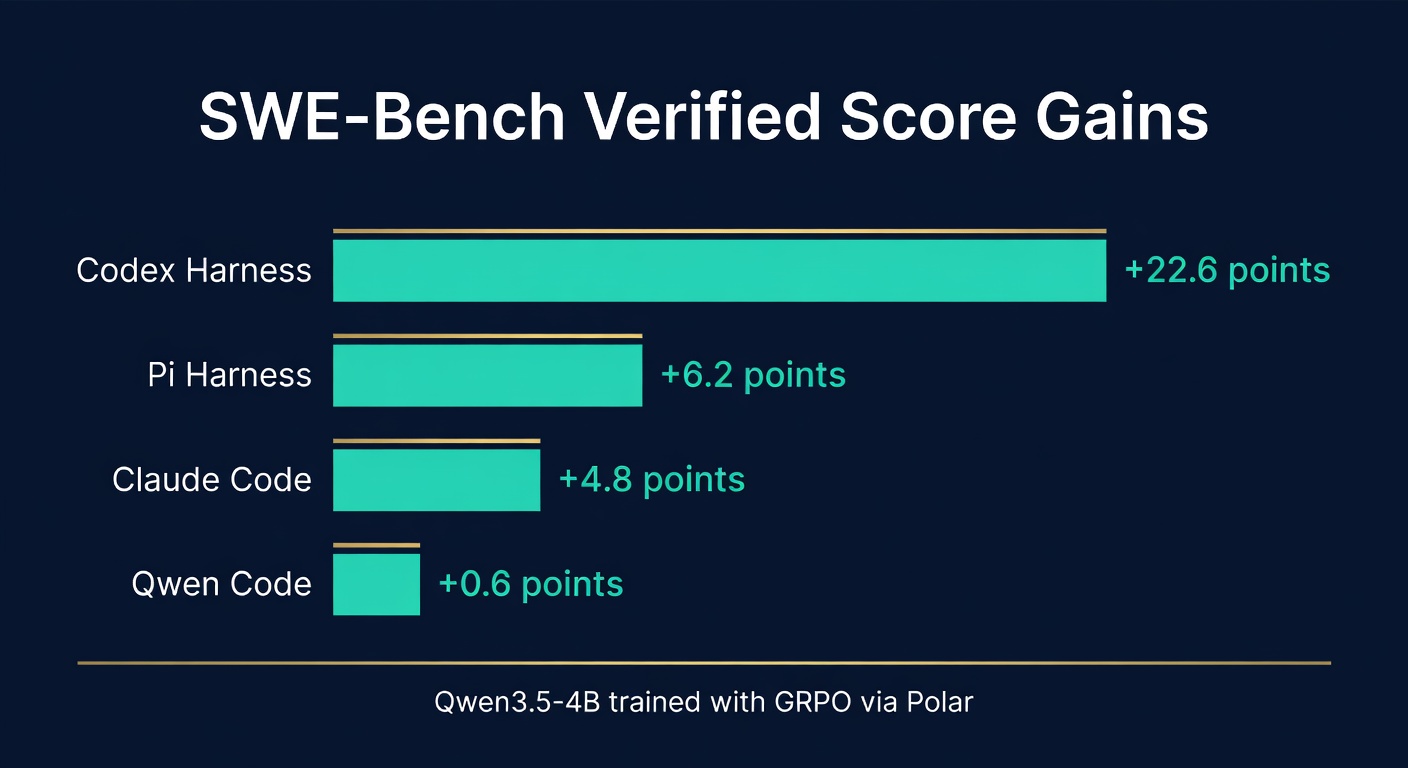
Codex harness (baseline 3.8% → Polar 26.4%):
- A gain of 22.6 percentage points. The model went from barely functional to genuinely useful.
- This is the largest jump in the results, which makes sense: Codex's harness had the most room for improvement.
Claude Code harness (baseline 29.8% → Polar 34.6%):
- A gain of 4.8 points on top of an already strong baseline.
- Claude Code is already well-optimized. Getting 4.8 points on top of 29.8% is significant.
Pi harness (baseline 34.2% → Polar 40.4%):
- A gain of 6.2 points, reaching the highest absolute score.
- Pi's harness was already the strongest baseline, and Polar pushed it even further.
Training speed with prefix merging:
- 5.39× faster than per-request reconstruction
- GPU utilization jumped from 20.4% to 87.7%
- Accuracy held steady at 87.7% of the per-request approach
The prefix merging technique is worth understanding. By default, each API call becomes its own training trace, which is safe but slow and wasteful. Prefix merging reconstructs longer chains of related calls into single trajectories, dramatically improving GPU utilization without sacrificing quality.
Quick answer: On SWE-Bench Verified, Polar improved a 4B model's performance by up to 22.6 points (Codex harness: 3.8% → 26.4%). With prefix merging, training runs 5.39× faster with 87.7% GPU utilization versus 20.4%. The Pi harness reached 40.4%, the highest score in the study.
Why Does This Matter for Businesses Building AI Agents?
If you're a company building products powered by AI agents (and let's be honest, that's most technology companies now), Polar changes the economics of agent development.
You don't need a ML research team to apply RL. Previously, applying RL to your agent meant hiring specialized engineers who understood both reinforcement learning and your agent's internals. Polar makes it possible to treat RL as a post-training optimization step that any competent engineer can run.
Closed-source tools are no longer locked out. If your workflow uses Claude Code, Codex CLI, or any other proprietary agent, you can now apply RL training to improve its performance on your specific tasks. You couldn't do this before. Period.
The cost structure is better. Prefix merging gives you 5.4× faster training with nearly 90% GPU utilization. That's not a marginal improvement. It's the difference between "too expensive to iterate" and "we can run experiments daily."

Practical implications for different teams:
- Product teams can A/B test RL-trained agents against vanilla agents with real production tasks
- Engineering teams can treat agent training as a CI/CD step rather than a research project
- Leadership can invest in agent optimization without committing to custom infrastructure
The 4B model results are particularly relevant for cost-conscious businesses. If a small model trained with Polar can reach 26-40% on SWE-Bench, that's a model you can run cheaply at scale, far cheaper than calling GPT-4 or Claude for every task.
Quick answer: Polar lets businesses apply RL training to any AI agent, including closed-source tools like Claude Code, without specialized ML engineers. With 5.4× faster training and high GPU utilization, it makes agent optimization economically viable for any team, not just research labs.
What About Trajectory Reconstruction and Token Faithfulness?
One of the subtle challenges in proxy-based training is making sure the training data actually matches what the agent did. If your training trajectory says the agent chose token X but the agent actually chose token Y, you're training on corrupted data.
Polar addresses this with token-faithful reconstruction. Every trainable token in the reconstructed trajectory matches the agent's actual behavior policy. No approximations. No shortcuts.
The reconstruction approaches:
- Per-request reconstruction. Each API call becomes one trace. Conservative and accurate, but fragments multi-step sessions. Low GPU utilization (20.4%).
- Prefix merging. Reconstructs longer chains by identifying shared prefixes across related API calls. 5.39× faster training, 87.7% GPU utilization, maintains trajectory quality.
The choice between these isn't just about speed. Per-request reconstruction gives you more granular reward signals: each trace can be independently scored. Prefix merging trades some granularity for massive efficiency gains.
For most production use cases, prefix merging is the right default. The accuracy trade-off is minimal (the paper shows maintained performance), and the speed improvement is transformational.
What's Next: Open Data, NeMo Gym, and the Road Ahead
NVIDIA isn't just releasing a framework. They're building an ecosystem.
Offline data generation. Using Qwen3.5-122B-A10B with the Pi harness on SWE-Gym, the team generated 504 accepted trajectories from 1,638 attempts, a 30.8% acceptance rate. This dataset is released on HuggingFace under the Apache 2.0 license.
This is significant because high-quality agent trajectory data is extremely scarce. Most RL training for agents has been limited by the lack of good demonstration data. Having 504 verified trajectories from a 122B model is a genuine contribution to the open-source community.
NeMo Gym integration. Polar is registered as a NeMo Gym environment, which means it plugs into NVIDIA's broader training ecosystem. If you're already using NeMo for model training, adding agent RL is now a configuration change, not an architecture redesign.
The predecessor context. Polar builds on ProRL Agent, NVIDIA's earlier work on reinforcement learning for agents. The jump from ProRL to Polar is primarily about generality: ProRL required more integration work, while Polar's proxy-based approach works with anything.
What I'm watching for:
- Community adoption and whether third-party harnesses get official Polar support
- Whether the offline dataset enables new forms of transfer learning for agent training
- How the cost-effectiveness of small models + Polar RL compares to simply using larger frontier models
Quick answer: NVIDIA released 504 verified agent trajectories as an open dataset on HuggingFace (Apache 2.0). Polar integrates with NeMo Gym, and builds on their earlier ProRL Agent work. The key question going forward: can small models trained with Polar match frontier model performance at a fraction of the cost?
The Bottom Line
Polar solves a real problem that has been blocking practical RL training for AI agents. The proxy-based approach is clean, the results are strong, and the infrastructure decisions (prefix merging, async worker pools, multi-API support) show that NVIDIA is thinking about production use, not just research demos.
For businesses, the message is clear: you can now optimize your AI agents with RL regardless of what tools they're built on. That wasn't true before. And with the efficiency gains from prefix merging, it's affordable enough to actually do.
The 4B model results are the headline, but the real story is the infrastructure. Making RL training work with any harness, any API, any agent: that's the unlock. Everything else follows from that.
Further reading: The full paper is available at arXiv:2605.24220. The dataset is on HuggingFace under Apache 2.0.
AJ Awan is the founder of Flowtivity, an AI consultancy specializing in workflow automation and agent-based solutions. He has 9+ years of consulting experience including 6 years at EY as Manager IT Advisory, TOGAF 9 certified, with $15M+ in delivered business benefits across clients including IAG, Genesis Care, CBA, and Westpac.