Last Updated: May 10, 2026
Most businesses in 2026 are renting intelligence. Every time your AI agent reads an email, generates a report, or processes a document, you pay per token. At scale, that adds up to thousands per month. And your data, your processes, and your competitive advantage flow through someone else's servers.
There is another way. You can own your AI infrastructure outright. Run models on your own hardware. Expose them via an API that works identically to OpenAI. Pay zero per-token costs. Keep every byte of data in your building.
This is practical now. The hardware exists, the models are open-source, and the setup takes an afternoon. Here is how.

The Problem With Renting Intelligence
OpenAI's pricing in 2026 tells the story. GPT-5.5 costs $5.00 per million input tokens and $30.00 per million output tokens. GPT-5.4 costs $2.50/$15.00. Want data residency (required for Australian Privacy Act compliance)? Add a 10% uplift. Running agents that process hundreds of requests daily? The costs compound fast.
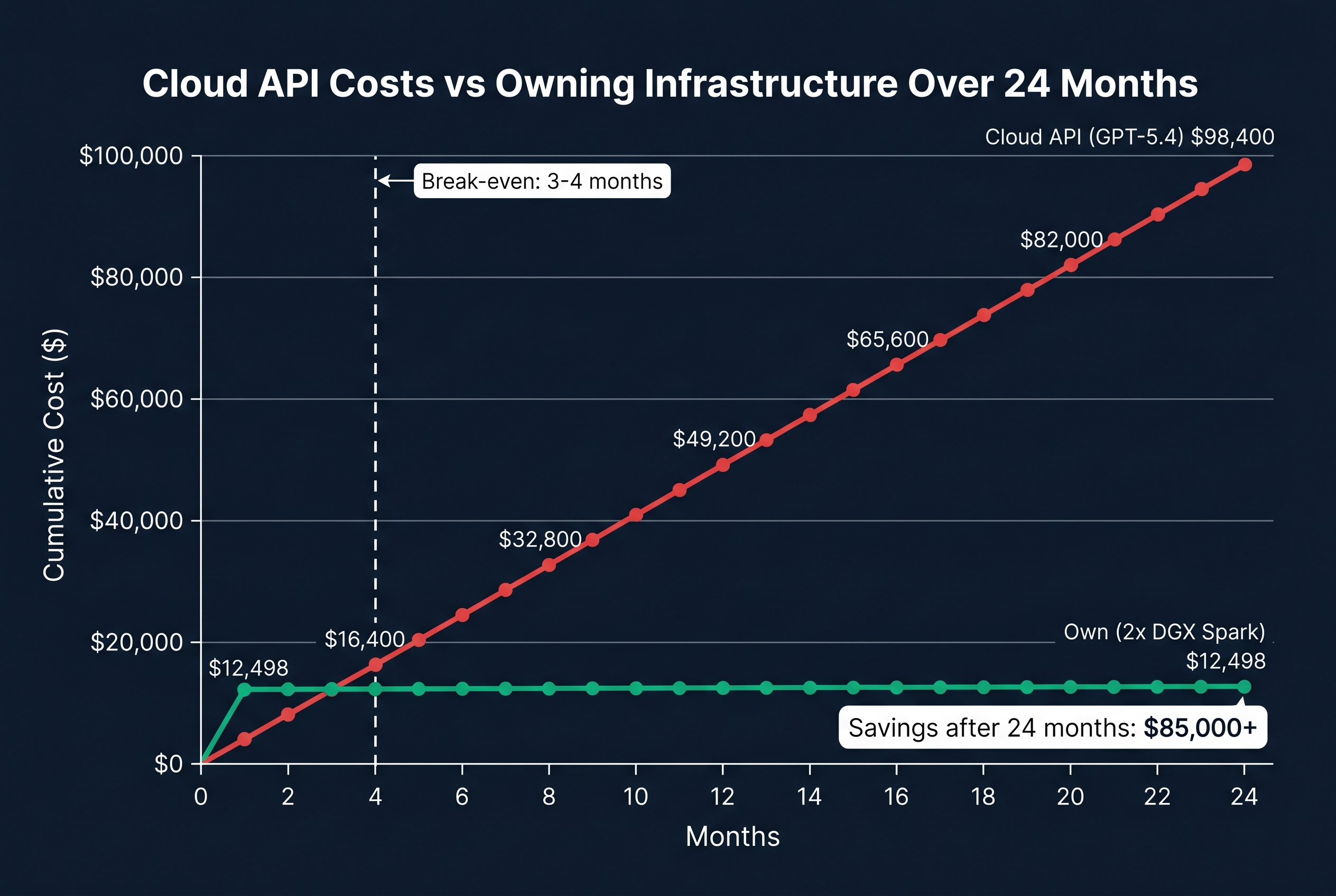
A business processing 500 documents per day through GPT-5.4 spends roughly $2,000-$4,000 per month on token costs alone. An insurance agency processing 500+ risk documents daily was spending $8,000/month before switching to self-hosted infrastructure. At 50 users or more, the math flips: owning hardware becomes cheaper within 8-14 months.
But cost is not the only problem. When your AI agents run on cloud APIs, your data leaves your control. Your proprietary processes, client information, and competitive intelligence pass through third-party servers. For businesses subject to the Privacy Act, healthcare regulations, or government contracts, this is a compliance risk, not just a cost issue.
There is also vendor dependency. When OpenAI changes pricing, deprecates a model, or experiences an outage, your business is at their mercy. You cannot switch models easily because your agent code is tightly coupled to one provider's API.
The Hardware: NVIDIA DGX Spark
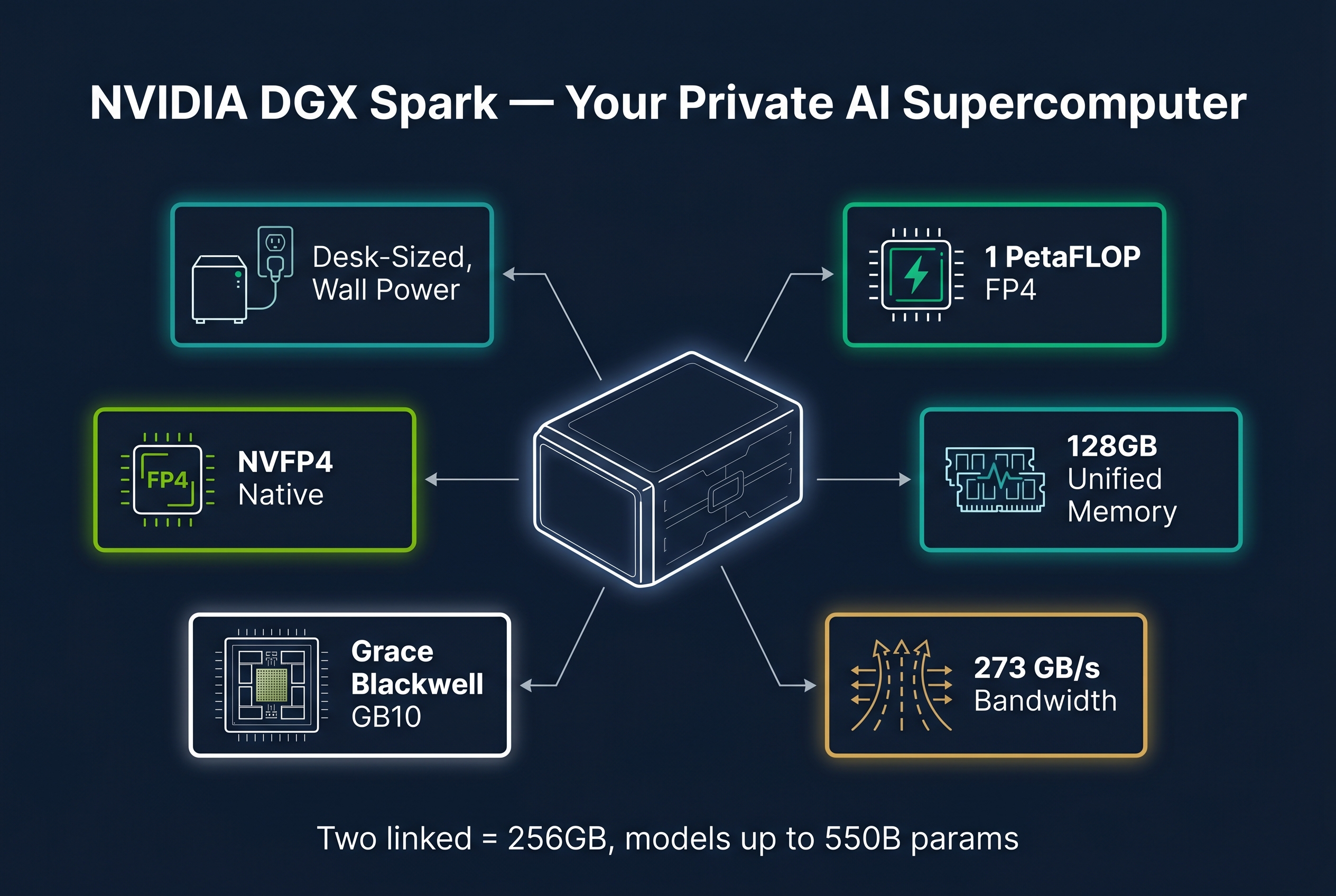
The NVIDIA DGX Spark is a compact supercomputer designed specifically for running AI workloads locally. It is not a gaming PC with a GPU bolted on. It is purpose-built AI infrastructure.
Key specifications:
- Grace Blackwell GB10 chip with 1 petaFLOP of FP4 AI compute performance
- 128GB unified coherent memory (shared between CPU and GPU)
- 273 GB/second memory bandwidth
- NVFP4 native support (Blackwell's efficient quantization format)
- Pre-installed: DGX OS (Ubuntu 24.04), CUDA 13.0, Docker, Ollama
- Power: Standard wall outlet, fits on a desk
- Noise: Quiet enough for an office, not a data centre
Two DGX Sparks can be linked via a QSFP/CX7 direct cable to form a 256GB unified cluster. This is enough memory to run models up to 550 billion parameters locally.
Australian pricing (as of May 2026):
- NVIDIA Founder's Edition (4TB): $8,999 AUD (PLE, VIC)
- ASUS variant (1TB): $6,249 AUD (Centrecom, VIC)
- Scorptec Brisbane (Slacks Creek): Call for stock and pricing
Two Sparks at $6,249 each = $12,498 AUD for your entire private AI infrastructure. No recurring costs. No per-token fees. No data leaving your building.
The Models: Nemotron 3 Family
NVIDIA's Nemotron 3 family is purpose-built for DGX Spark hardware. These are not general-purpose models adapted for the hardware. They are designed from the ground up for Blackwell's architecture, pre-trained in NVFP4 format, and delivered as NIM microservices for peak inference performance.
Three models, three roles:
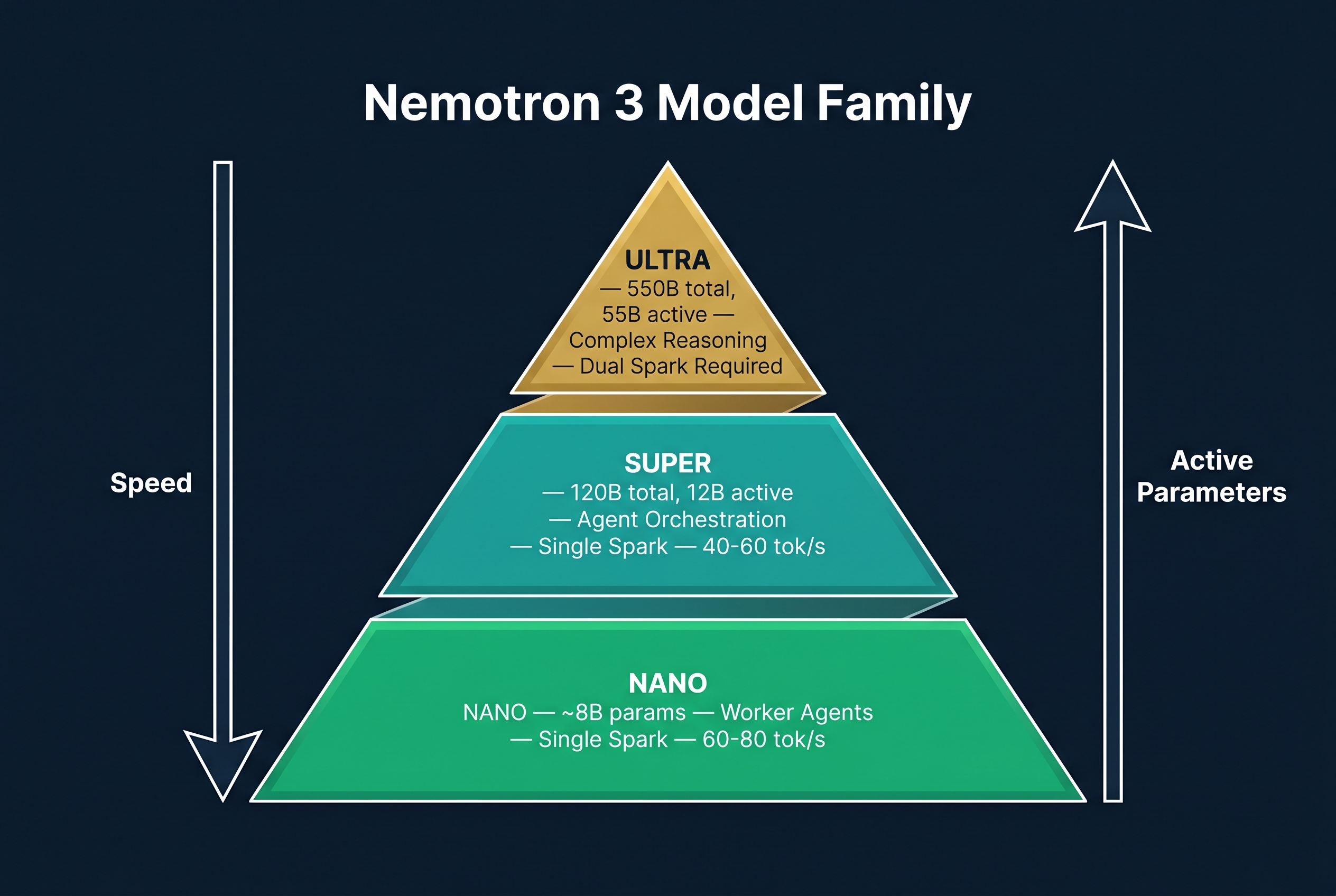
Nemotron 3 Nano — The worker bee. Small, fast, multimodal. Designed for sub-agent tasks like perception, context maintenance, and parallel processing. Outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Runs on a single Spark with resources to spare.
Nemotron 3 Super — The orchestrator. 120B total parameters, 12B active per token via hybrid Mamba-Transformer Mixture-of-Experts architecture. Includes built-in speculative decoding via MTP layers (no separate draft model needed). Achieves 7.5x higher throughput than Qwen 3.5 122B on long output tasks. Supports 1M token context. 85.6% on PinchBench (agent task benchmark), making it the top open model for agentic workloads. Runs on a single Spark.
Nemotron 3 Ultra — The heavy brain. 550B total parameters, 55B active per token. State-of-the-art reasoning and accuracy. Requires dual Spark cluster in combined mode (256GB). For complex architecture design, deep research, and tasks that need frontier-level reasoning.
How do they compare to popular alternatives?
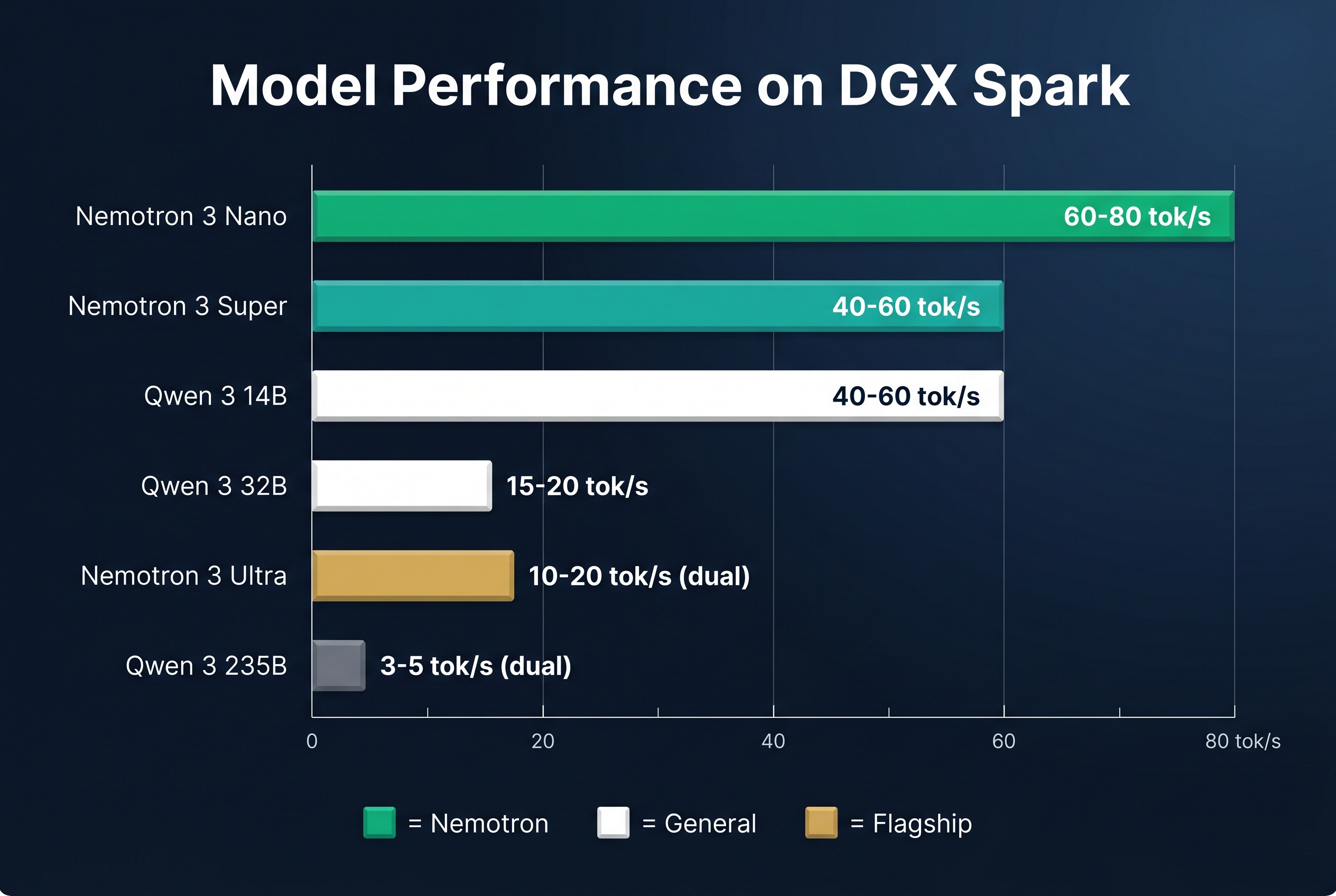
| Model | Size | Active | Best For | Est. tok/s (Spark) |
|---|---|---|---|---|
| Nemotron 3 Nano | ~8B | ~8B | Worker agents, multimodal | 60-80 |
| Nemotron 3 Super | 120B | 12B | Agent orchestration, high-volume | 40-60 |
| Nemotron 3 Ultra | 550B | 55B | Complex reasoning, frontier-level | 10-20 (dual) |
| Qwen 3 235B | 235B | 235B | General reasoning | 3-5 (dual) |
| Qwen 3 32B | 32B | 32B | General purpose | 15-20 |
| Qwen 3 14B | 14B | 14B | Fast tasks | 40-60 |
| DeepSeek V4 | ~670B | MoE | Best open-weight reasoning | 2-4 (dual) |
The key insight: Nemotron models run faster on DGX Spark than general models because they are compiled for Blackwell's FP4 pipeline and memory layout. They also include native speculative decoding, which boosts generation speed without needing a separate draft model.
Two Operating Modes: Split and Combined
Your dual DGX Spark cluster has two operating modes. Switching between them takes 2-3 minutes (config change + model reload, no hardware changes).
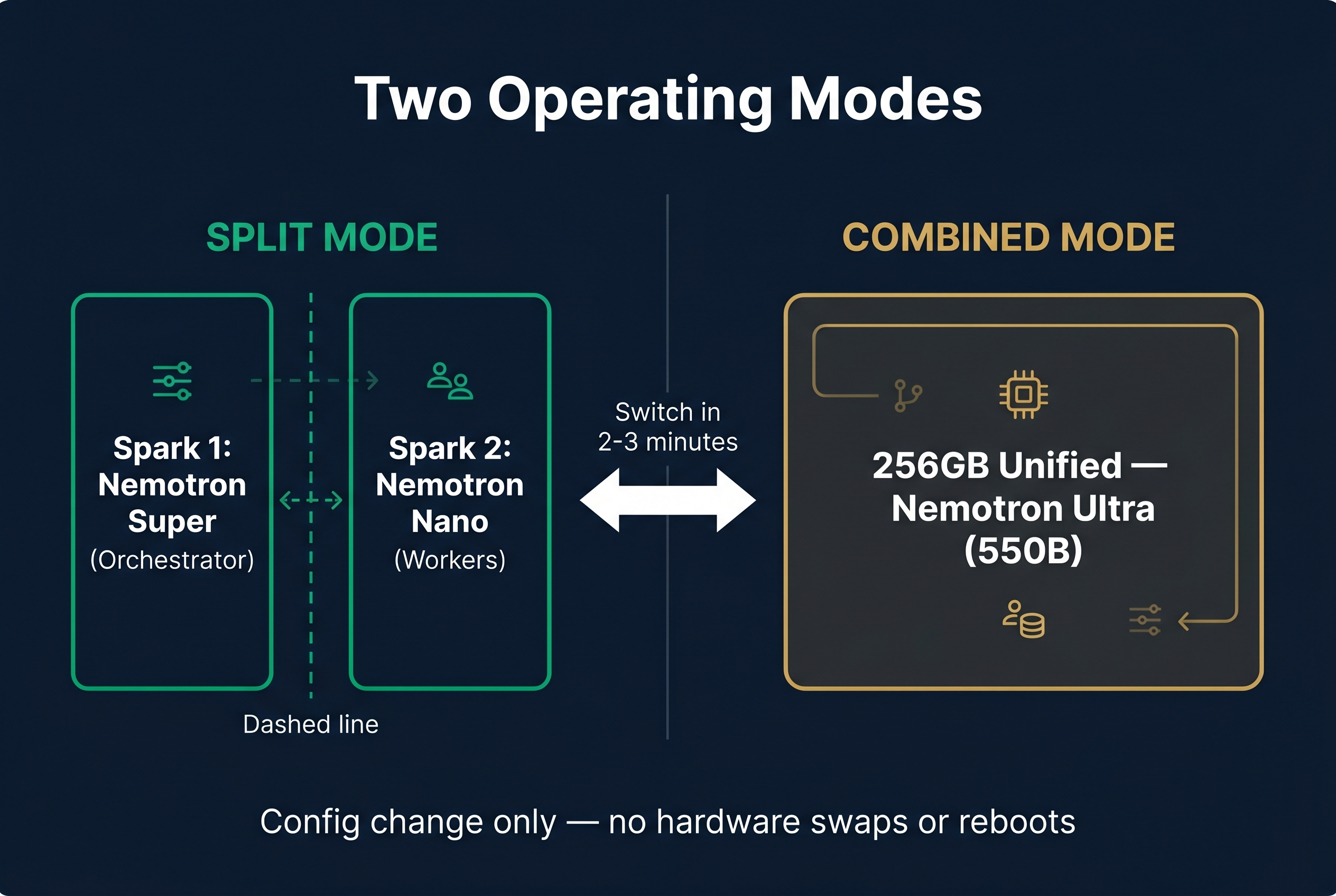
Split mode (default, 95% of the time):
- Spark 1 runs Nemotron 3 Super (orchestrator, 40-60 tok/s)
- Spark 2 runs Nemotron 3 Nano or Qwen 14B (parallel workers, 60-80 tok/s)
- Each Spark operates independently
- Best for: daily agent operations, multiple concurrent tasks, real-time chat
Combined mode (5% of the time):
- Both Sparks pool 256GB memory via Ray + vLLM distributed inference
- Runs Nemotron 3 Ultra (550B) as one model across both GPUs
- Best for: deep research, architecture design, complex analysis that needs frontier-level reasoning
You can script the mode switch and swap in under 3 minutes. No cable changes, no reboots.
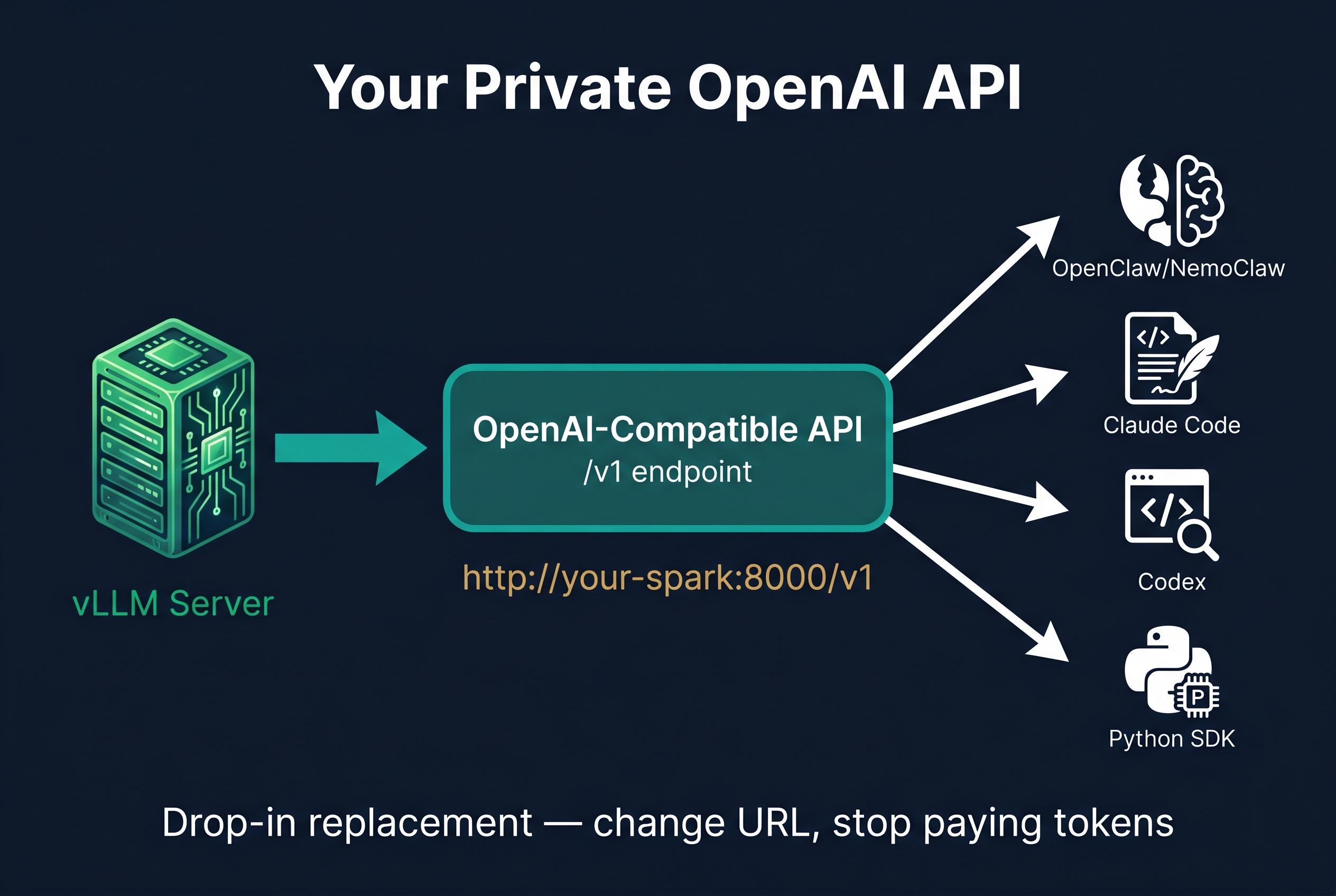
Exposing Your Models as an API
This is where it gets powerful. Your DGX Spark runs vLLM, which serves an OpenAI-compatible API out of the box. Every tool that speaks OpenAI's API works instantly with your local hardware.
Starting the API server:
python -m vllm.entrypoints.openai.api_server \
--model nvidia/Nemotron-3-Super-120B-A12B-NVFP4 \
--dtype fp4 \
--max-model-len 32768 \
--host 0.0.0.0 \
--port 8000
Your Spark is now an OpenAI API endpoint at http://192.168.x.x:8000/v1
Any OpenAI-compatible tool connects instantly:
- OpenClaw and NemoClaw agent frameworks
- Claude Code, Codex, Cursor
- LangChain, LlamaIndex
- Python
openaiSDK - Even
curlfor testing
For split mode (2 models, 2 APIs):
# Spark 1: Orchestrator
vllm serve nvidia/Nemotron-3-Super-120B-A12B-NVFP4 --port 8000
# Spark 2: Workers
vllm serve nvidia/Nemotron-3-Nano-NVFP4 --port 8001
For external access (from your EC2 instance, phone, anywhere in the world):
Put Caddy or nginx in front with HTTPS and authentication:
ai.yourhouse.com {
reverse_proxy localhost:8000
basicauth * {
yourname $2a$14$hashed_password
}
}
Now https://ai.yourhouse.com/v1 is your private, encrypted, authenticated OpenAI replacement. Accessible from anywhere. Zero per-token cost. Your own private GPT.
The Performance Optimisation Stack
The benchmarks you see in Reddit threads are usually running plain Ollama with no optimisation. The real performance comes from NVIDIA's optimised inference stack:
TensorRT-LLM: NVIDIA's inference engine with kernel-level optimisations and efficient memory layouts. 1.5-2x faster than plain Ollama on the same hardware.
Speculative decoding: A small model guesses tokens, the big model verifies in batch. Nemotron 3 Super has this built-in via MTP layers, no separate draft model needed. 2-3x speedup on generation.
NVFP4 quantisation: Blackwell's native 4-bit format. Halves memory usage with minimal quality loss because the model was pre-trained in this format, not quantised after the fact.
CES 2026 software update: NVIDIA shipped a 2.5x performance improvement through TensorRT-LLM optimisations and speculative decoding improvements. This is a software update, not new hardware.
Practical example: Nemotron 3 Super with the full optimisation stack on a single DGX Spark should deliver 40-60 tokens per second for agent orchestration tasks. That is faster than GPT-5.4 for most agentic workloads, with zero cost per request.
The ROI: When Does Owning Beat Renting?
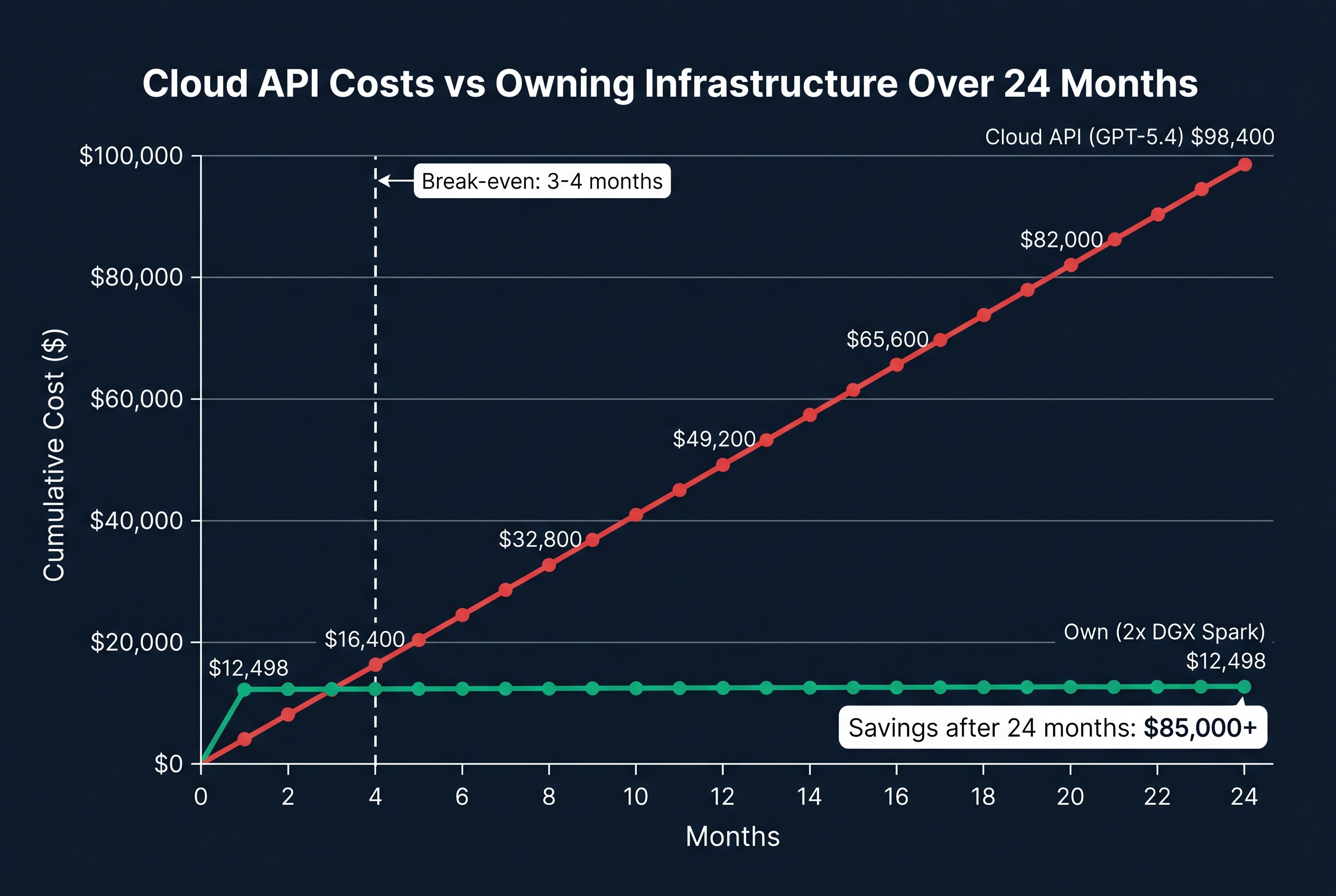
Scenario: Mid-size business, 50 agents running daily
Cloud approach (GPT-5.4 at $2.50/$15.00 per million tokens):
- 500,000 input tokens/day + 100,000 output tokens/day per agent
- 50 agents = 25M input + 5M output tokens daily
- Daily cost: ~$137/day = ~$4,100/month = ~$49,200/year
Own approach (2x DGX Spark at $12,498):
- Hardware: $12,498 (one-time)
- Electricity: ~$50/month (two 170W units, 24/7)
- No per-token costs
- Year 1 total: $13,098
- Year 2 total: $600 (electricity only)
Break-even: 3-4 months.
Even for smaller deployments (10 agents), the break-even is 12-18 months. For businesses with compliance requirements (Privacy Act, health data, government contracts), the data sovereignty benefit alone justifies the investment regardless of cost savings.
Australian Data Sovereignty
Running AI on your own hardware in your own building is the strongest data sovereignty position possible. No data crosses borders. No third party processes your information. No cloud provider can be compelled to hand over your data.
This matters for:
- Privacy Act compliance (amendments effective December 2026)
- Health data (HIPAA-equivalent Australian requirements)
- Government contracts (security cleared workloads)
- Client confidentiality (legal, financial services)
- Competitive intelligence (proprietary processes and data)
When your AI agent reads a client's financial records to generate a report, that data stays in your building. When your agent processes health information from tenders, it never touches a US cloud provider's servers. This is not just compliance. It is trust.
What This Means for Your Business
You do not need to be a technology company to run private AI infrastructure. The DGX Spark is designed to be set up in an afternoon. The models are open-source. The API is OpenAI-compatible. If your team can configure an API key, they can use your private AI infrastructure.
The practical path:
- Purchase 2x DGX Spark units ($12,498 AUD total)
- Connect them via QSFP/CX7 cable (included)
- Install vLLM and load Nemotron models (one afternoon)
- Expose the API endpoint on your network
- Point your existing tools at your private API instead of OpenAI
- Stop paying per-token costs forever
For businesses that want help with setup, architecture, and compliance integration, Flowtivity provides end-to-end deployment services. We design the architecture, configure the models, set up the API layer, and integrate with your existing agent frameworks and compliance requirements.
The Bottom Line
Renting intelligence was necessary when the hardware did not exist and the models were not open-source. In 2026, both problems are solved. You can own your AI infrastructure outright for less than one year of cloud API costs.
The businesses that own their intelligence layer will have a structural advantage over those that rent. Lower costs. Full data control. No vendor dependency. The ability to run any model, any time, for zero marginal cost.
The question is not whether you can afford to own your AI infrastructure. It is whether you can afford not to.
About the author: AJ Awan is the founder of Flowtivity, an Australian AI consultancy specializing in workflow automation and AI agent deployment for growing businesses. With 9+ years of consulting experience including 6 years at EY, AJ helps companies build private AI infrastructure that eliminates per-token costs while meeting Australian compliance requirements.