Nvidia's Qwen3.6-27B-NVFP4: 27B Parameter AI Now Runs on Consumer Blackwell GPUs
Last Updated: July 1, 2026
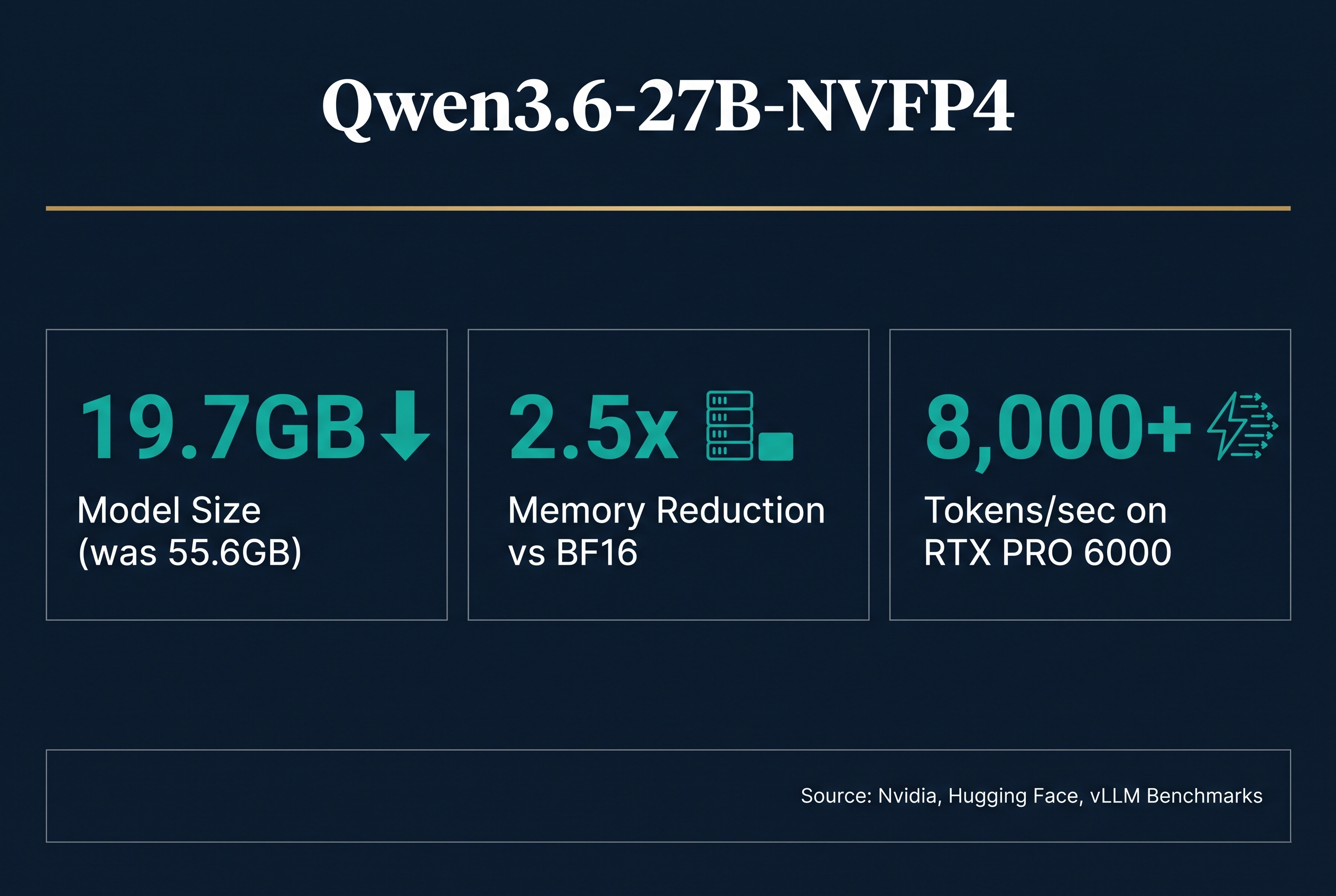
On June 26, 2026, Nvidia quietly dropped a bomb on Hugging Face: nvidia/Qwen3.6-27B-NVFP4. It's a 4-bit quantized version of Alibaba's flagship 27-billion-parameter Qwen3.6 model, compressed from 55.6GB down to 19.7GB using Nvidia's proprietary NVFP4 format. The result? A model that punches in the same weight class as Claude and GPT-4 on coding tasks, but fits on a single consumer-grade Blackwell GPU.
Hugging Face CTO Julien Chaumond flagged the release, and for good reason. This isn't just another quantization — it's Nvidia flexing their Blackwell architecture to make open-source AI dramatically more practical.
What Is Qwen3.6-27B and Why Does It Matter?
Qwen3.6-27B is Alibaba's dense 27-billion-parameter multimodal language model, open-sourced on April 21, 2026. It accepts text, image, and video inputs, supports a native 262K token context window (extendable to over 1 million tokens), and was specifically engineered for agentic coding workflows.
The key breakthrough is that Qwen3.6-27B achieves flagship-level coding performance at a fraction of the size of competing models. On SWE-bench Verified — the gold standard for evaluating AI coding agents — it scores 77.2%, surpassing the much larger Qwen3.5-397B-A17B (76.2%) and matching Claude 4.5 Opus on Terminal-Bench 2.0 at 59.3%.
The model's standout capabilities include:
- Agentic coding: Multi-step instruction following, project structure understanding, and cross-file consistency
- Thinking Preservation: Retains chain-of-thought reasoning across multi-turn conversations for more stable outputs
- Multimodal reasoning: Processes images and video alongside text natively
- Repository-level understanding: Handles large codebases within its 262K+ context window
- Integration-ready: Works with OpenClaw, Claude Code, and Qwen Code
This is a model designed not just to generate code, but to function as a collaborative developer.
What Is NVFP4? Nvidia's 4-Bit Format Explained
NVFP4 is Nvidia's proprietary 4-bit floating-point quantization format, introduced with the Blackwell GPU architecture. Unlike traditional INT4 quantization (which uses integers), NVFP4 uses floating-point representation — specifically the E2M1 format: 1 sign bit, 2 exponent bits, and 1 mantissa bit.
The format delivers:
- ~3.5x memory reduction compared to FP16
- ~1.8x memory reduction compared to FP8
- Under 1% accuracy loss on key language modeling benchmarks
- Native hardware acceleration on Blackwell's 5th-generation Tensor Cores (up to 4 PFLOPS on RTX PRO 6000)
The secret sauce is NVFP4's two-level scaling mechanism. Instead of applying one scaling factor to an entire tensor, the format divides elements into 16-element micro-blocks. Each block gets its own FP8 shared scale (determined by the maximum absolute value in the block), and a second-level FP32 scale is applied per tensor. This fine-grained approach confines outliers and minimizes quantization error — the reason accuracy barely degrades.
Think of it like a JPEG for neural networks: aggressive compression that preserves the important details.
The Benchmark Numbers: NVFP4 vs FP8
Nvidia published a comprehensive evaluation comparing NVFP4 against FP8 on their GB300 hardware across nine benchmarks. The results are striking:
Benchmark Comparison (NVFP4 vs FP8):
- MMLU Pro: 86.3 vs 86.1 (NVFP4 actually wins)
- GPQA Diamond: 85.5 vs 86.0 (0.5 point difference)
- HLE: 21.8 vs 21.7 (statistically identical)
- τ²-Bench Telecom: 95.4 vs 95.2 (NVFP4 wins again)
- MMMU Pro: 74.3 vs 74.6 (negligible gap)
- SciCode: 44.5 vs 44.8 (within margin of error)
- AIME 2025: 92.7 vs 93.1 (0.4 point difference)
- AA-LCR: 68.3 vs 68.8 (negligible)
- IFBench: 65.5 vs 65.1 (NVFP4 wins)
The takeaway: across nine diverse benchmarks spanning language understanding, graduate-level science, coding, math, agentic tool-use, multimodal reasoning, and long-context recall, NVFP4 performs identically to FP8. Not "close enough" — in four out of nine benchmarks, it actually scores higher.
Real-World Hardware Performance: RTX PRO 6000 vs DGX Spark
The theoretical specs matter because of what they enable in practice. Here's what NVFP4 actually delivers on real hardware:
RTX PRO 6000 Blackwell (96GB GDDR7, 1,792 GB/s bandwidth)
The RTX PRO 6000 is the card that makes 27B parameter models trivial. With NVFP4:
- Single-user throughput: 6,000-8,000 tokens/sec on 27B-class models
- vs A100: 1.7-2x higher throughput under identical conditions
- Concurrent serving: 5,160 tokens/sec on Qwen-14B at 300 concurrent requests
- NVFP4 vs BF16 throughput: 1.9-2.1x improvement at concurrency 8-64
- Time to first token: 148ms at concurrency 64 (vs 338ms for BF16)
For perspective: the RTX PRO 6000 delivers roughly 4-7x more tokens per second than the DGX Spark across all tested models.
DGX Spark (128GB unified LPDDR5X, 273 GB/s bandwidth)
The DGX Spark is the desktop-class option. While its bandwidth is lower, its 128GB unified memory means it can fit models the RTX PRO 6000 can't at full precision:
- NVFP4 vs AWQ: ~20% faster than INT4 quantization
- 80B model with MTP: 111.9 tokens/sec at short sequences
- Qwen3.6-35B-A3B-NVFP4: 190-270 tokens/sec depending on workload type
The MTP Accelerator: Free Speedup on Top of NVFP4
Multi-Token Prediction (MTP) is where throughput gets genuinely absurd. MTP is a form of speculative decoding where the model itself has integrated prediction heads that forecast multiple future tokens in a single forward pass — no separate draft model needed.
When combined with NVFP4 on Blackwell hardware:
- 2-3x faster inference compared to standard autoregressive decoding
- 18-24% additional throughput on top of NVFP4's baseline gains
- Zero quality degradation — all predictions are verified by the model before acceptance
- Qwen3.6-35B-A3B with MTP: 1,726 tokens/sec on decode-heavy workloads (RTX PRO 6000)
The model generates an initial token, its MTP heads draft several subsequent tokens, and the model verifies them all in one pass. Accepted tokens get appended; rejected ones get discarded. The output is mathematically identical to standard autoregressive generation.
For developers serving Qwen3.6-27B-NVFP4 with vLLM, MTP is essentially a toggle that gives you free throughput.
How to Deploy Qwen3.6-27B-NVFP4 Today
The model is live on Hugging Face under the Apache 2.0 license — free for commercial and non-commercial use.
Serving with vLLM (recommended):
vllm serve nvidia/Qwen3.6-27B-NVFP4 \
--port 8000 \
--quantization modelopt \
--max-model-len 262144 \
--reasoning-parser qwen3
Supported hardware:
- NVIDIA Blackwell (RTX PRO 6000, B200, GB200, GB300, DGX Spark)
- NVIDIA Hopper (H100, H200) with reduced NVFP4 benefit
Supported runtime: vLLM (nightly or latest stable)
The model was quantized using Nvidia's Model Optimizer (v0.45.0), with weights and activations of linear operators within transformer blocks quantized to NVFP4. Non-linear operations remain at higher precision.
What This Means for the AI Ecosystem
Nvidia's release of Qwen3.6-27B-NVFP4 signals three important shifts:
1. Open-source models are closing the gap fast. A 27B parameter model that scores 77.2% on SWE-bench Verified — competitive with Claude Opus 4.6 — running on consumer hardware is a paradigm shift. You no longer need API credits to get frontier-level coding assistance.
2. Quantization is no longer a compromise. NVFP4's two-level scaling means the accuracy tax for running at 4-bit is effectively zero. The benchmarks prove it — in some cases, NVFP4 outperforms FP8. The era of "quantization hurts quality" is over for Blackwell users.
3. Nvidia is weaponizing their hardware advantage. NVFP4 only runs on Blackwell. If you want the best open-source model performance, you need Nvidia's latest silicon. It's a moat disguised as an open-source contribution.
For developers and businesses, the practical implication is clear: a $4,000 RTX PRO 6000 card can now serve a model that rivals paid API offerings, with full data sovereignty, zero per-token costs, and the ability to fine-tune on proprietary data. The economics fundamentally change when your coding agent runs locally at 2,000+ tokens/sec.
Frequently Asked Questions
What is NVFP4 quantization?
NVFP4 is Nvidia's 4-bit floating-point format introduced with the Blackwell GPU architecture. It reduces model memory usage by approximately 3.5x compared to FP16 while maintaining accuracy within 1% of the original model. It uses a two-level scaling system with 16-element micro-blocks to minimize quantization error.
How accurate is Qwen3.6-27B-NVFP4 compared to the full-precision model?
Across nine benchmarks tested by Nvidia (including MMLU Pro, GPQA Diamond, SciCode, and AIME 2025), NVFP4 scores within 0.5 points of FP8 on average. In four benchmarks, NVFP4 actually scored higher than FP8. The accuracy loss is negligible for real-world applications.
Can I run Qwen3.6-27B-NVFP4 on consumer hardware?
Yes. The NVFP4 version is 19.7GB, which fits on a single RTX PRO 6000 Blackwell (96GB) with room to spare, or on a DGX Spark (128GB unified memory). On RTX 4090 (24GB), it can run with 4-bit quantization at reduced performance. The model requires Blackwell architecture for native NVFP4 acceleration.
How fast is Qwen3.6-27B-NVFP4 on Blackwell GPUs?
On an RTX PRO 6000 Blackwell, NVFP4 delivers approximately 6,000-8,000 tokens/sec for single-user inference on 27B-class models. With Multi-Token Prediction (MTP) speculative decoding enabled, throughput increases by an additional 18-24%. Time to first token at concurrency 64 is 148ms.
Is Qwen3.6-27B-NVFP4 free for commercial use?
Yes. The model is released under the Apache 2.0 license, which permits both commercial and non-commercial use without restrictions. You can deploy it in production systems, fine-tune it, and distribute it freely.
What is Multi-Token Prediction (MTP) in vLLM?
MTP is a speculative decoding technique where the model has integrated prediction heads that forecast multiple tokens per forward pass. Unlike traditional speculative decoding (which requires a separate draft model), MTP adds no VRAM overhead and produces output identical to standard autoregressive generation. It delivers 18-24% throughput improvement on Blackwell GPUs.