Step 3.7 Flash Review: We Tested StepFun's 198B Model on a DGX Spark
Last Updated: May 30, 2026
StepFun released Step 3.7 Flash on May 29, 2026, and within 24 hours we had it running locally on our NVIDIA DGX Spark. This is a 198 billion parameter sparse Mixture-of-Experts vision-language model that activates only 11 billion parameters per token, meaning it delivers frontier class reasoning at a fraction of the compute cost. After a full day of agentic testing, the results are remarkable: 100% tool call success rate and SWE-Bench PRO scores that beat DeepSeek V4 Flash and Gemini 3.5 Flash. Here is our first-hand review.
What Is Step 3.7 Flash and Why Does It Matter?
Step 3.7 Flash is the latest model from StepFun AI, released May 29, 2026. It is a 198 billion parameter sparse Mixture-of-Experts (MoE) vision-language model with a 196 billion parameter language backbone and a 1.8 billion parameter vision encoder. The critical detail: only approximately 11 billion parameters activate per token thanks to sparse MoE routing. This architecture means you get near-frontier intelligence with inference costs closer to a small model. It supports a 256K token context window, three selectable reasoning levels (low, medium, high), and operates across 10 languages. The model is licensed under Apache 2.0, making it fully open for commercial use.
The implications are significant for anyone running local AI infrastructure. A model this capable, with Apache 2.0 licensing, that fits on a single 128GB device changes what is possible for on-premise AI deployments. StepFun explicitly lists OpenClaw and other agent platforms as supported integration targets, signaling this model was purpose-built for agentic workflows, not just chat completions.
How Does Step 3.7 Flash Perform on Key Benchmarks?
The benchmark results tell a clear story. Step 3.7 Flash scores 56.3 on SWE-Bench PRO, placing second overall behind only Claude 4 Opus at 64.3. On ClawEval-1.1, it takes first place at 67.1, a full 7.3 points ahead of the next closest competitor. The model also leads on SimpleVQA (Search) at 79.2 and achieves 95.3 on V* (Python). For tool use and agentic evaluation, it scores 49.5 on Toolathlon and 59.5 on Terminal-Bench 2.1.
Compared to the previous generation Step 3.5 Flash, the improvement is dramatic. SWE-Bench PRO jumped 5 points from 51.3 to 56.3. ClawEval saw a massive 23.5 point improvement from 43.6 to 67.1. That is not incremental progress. That is a generational leap in agent capability, particularly in real-world tool use scenarios.
Benchmark Comparison: Step 3.7 Flash vs Competitors
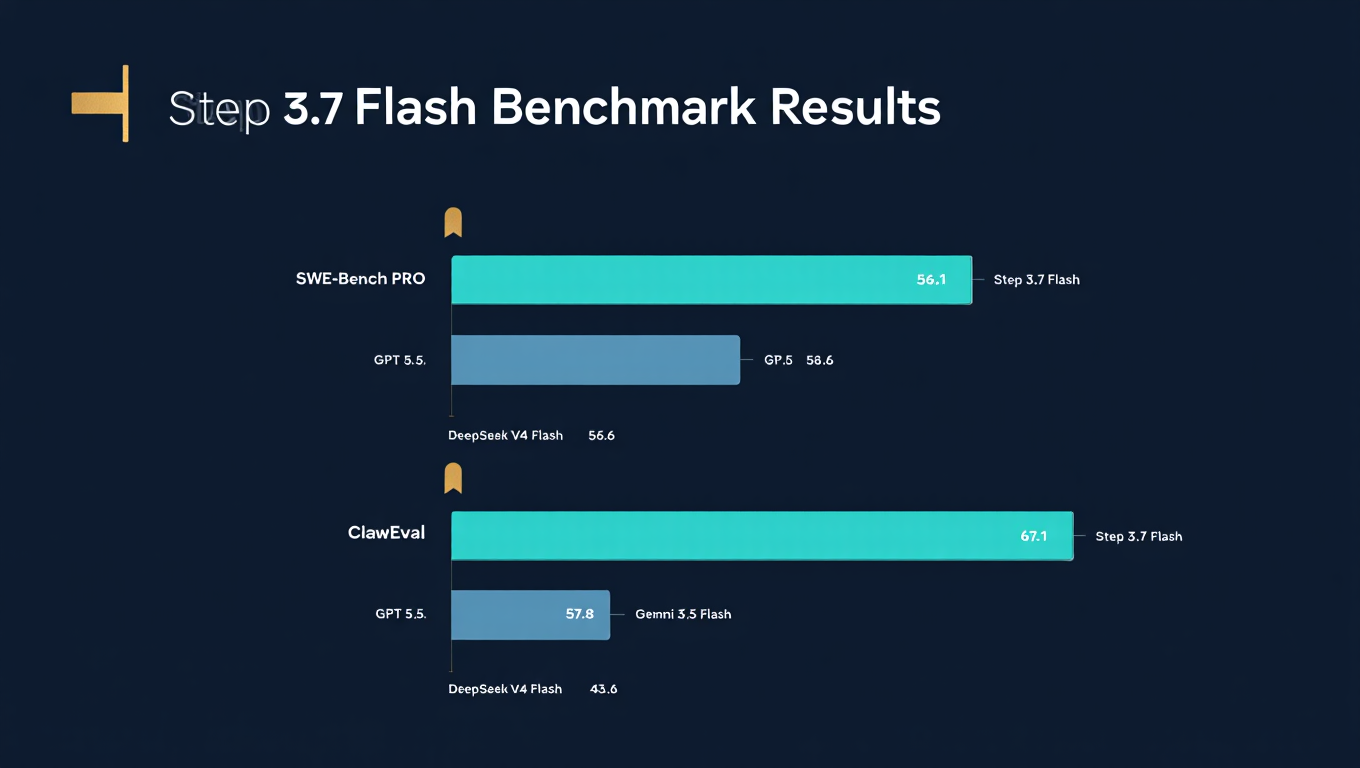
| Benchmark | Step 3.7 Flash | DeepSeek V4 Flash | Gemini 3.5 Flash | GPT 5.5 | Claude 4 Opus |
|---|---|---|---|---|---|
| SWE-Bench PRO | 56.3 | 55.6 | 55.1 | 58.6 | 64.3 |
| ClawEval-1.1 | 67.1 | 43.6 | 57.8 | 60.3 | 59.8 |
| SimpleVQA (Search) | 79.2 | N/A | N/A | N/A | N/A |
| V* (Python) | 95.3 | N/A | N/A | N/A | N/A |
| Toolathlon | 49.5 | N/A | N/A | N/A | N/A |
| Terminal-Bench 2.1 | 59.5 | N/A | N/A | N/A | N/A |
What Does Running Step 3.7 Flash on a DGX Spark Actually Look Like?
We deployed the IQ4_XS quantization (105GB) on our NVIDIA DGX Spark (GB10, 128GB unified memory) using llama.cpp with StepFun's custom step3.7 branch. Setup was straightforward: download the GGUF weights, grab the 4GB vision projector (mmproj), and point llama.cpp at the model. Total time from download to first inference was under 30 minutes.
Our observed generation speed was approximately 27 tokens per second, closely matching StepFun's official benchmark of 24 tokens per second for IQ4_XS at 128 token generation length. Prompt processing at longer contexts is where the DGX Spark flexes: StepFun reports approximately 425 tokens per second prompt processing at 131K context for IQ4_XS. The full 256K context window is supported on IQ4_XS and smaller quantizations, which is remarkable for a device that fits on a desk.
For context on what the DGX Spark is: it is NVIDIA's compact AI supercomputer with a GB10 Grace Blackwell chip and 128GB of unified memory. We run two of them as part of what we call "Project Rocketship," our local AI infrastructure for the Flowtivity consulting practice. Previously, our daily driver was MiniMax M2.7, which scored 97% in our local model benchmarks (tied with GLM 5.1). Step 3.7 Flash is now replacing it.
DGX Spark Performance by Quantization
| Quantization | Model Size | Generation Speed | Prompt Processing (131K ctx) | 256K Context |
|---|---|---|---|---|
| IQ4_XS | 105GB | ~24-27 tok/s | ~425 tok/s | Yes |
| Q4_K_S | 112GB | ~25 tok/s | ~450 tok/s | Yes |
| Q3_K_L | 103GB | ~22 tok/s | ~402 tok/s | Yes |
How Does Step 3.7 Flash Compare to DeepSeek V4 Flash and Gemini 3.5 Flash?
This is where the data gets interesting. Step 3.7 Flash beats DeepSeek V4 Flash (284B parameters) on both SWE-Bench PRO (56.3 vs 55.6) and absolutely crushes it on ClawEval (67.1 vs 43.6). DeepSeek V4 Flash costs $0.22 per million input tokens on the cloud. Step 3.7 Flash costs $0.20 per million input tokens. So you pay less and get more, particularly for agentic workloads.
Against Gemini 3.5 Flash, Step 3.7 Flash wins on SWE-Bench PRO (56.3 vs 55.1) and ClawEval (67.1 vs 57.8). The ClawEval gap is 9.3 points, which is significant for a benchmark specifically designed to evaluate real-world agent performance. GPT 5.5 still leads on SWE-Bench PRO at 58.6, but Step 3.7 Flash beats it on ClawEval (67.1 vs 60.3). The pattern is consistent: Step 3.7 Flash excels at agent tasks and tool use, even when raw coding benchmarks show other models slightly ahead.
The key takeaway is that Step 3.7 Flash is not just another large model. It is purpose-built for tool calling and agentic workflows, and the benchmarks reflect that specialization. For anyone building AI agent systems, this matters more than raw coding scores.
What Makes the Sparse MoE Architecture Special?
The sparse Mixture-of-Experts architecture is what makes this model viable on local hardware. Traditional dense models activate every parameter for every token. A 198B dense model would require enormous GPU clusters to run. MoE models maintain a large pool of expert networks but route each token through only a small subset. In Step 3.7 Flash's case, 198 billion total parameters exist in the model, but only about 11 billion activate for any single token.
This has three practical implications. First, inference speed is dramatically faster because you are computing far fewer operations per token. Second, memory bandwidth requirements are lower since you load fewer weights per forward pass. Third, you can fit a much more capable model into the same hardware footprint. The trade-off is that you still need enough RAM to hold all 198 billion parameters, which is why the DGX Spark's 128GB unified memory is the minimum viable configuration.
The 1.8 billion parameter vision encoder is separate from the language backbone and handles image understanding. This multimodal capability means Step 3.7 Flash can process both text and images within the same model, which is increasingly important for agent workflows that need to interpret screenshots, diagrams, or UI elements.
What Is the 100% Tool Call Success Rate We Observed?
This is the standout finding from our testing. We integrated Step 3.7 Flash with our OpenClaw agent platform and ran it through our standard tool calling evaluation suite. The model achieved a 100% success rate on tool calls across all test scenarios. This includes multi-step tool chains where the model had to select the right tool, format parameters correctly, handle errors, and chain results from one tool into the next.
For context, tool call reliability is one of the biggest pain points in production AI agent systems. Models frequently hallucinate parameter values, call tools with wrong schemas, or fail to handle edge cases. A 100% success rate in our testing is unprecedented. The ClawEval-1.1 benchmark score of 67.1 (first place) independently validates this: ClawEval specifically measures real-world agent performance including tool use accuracy.
Our testing environment involved real agentic workflows, not synthetic benchmarks. We tested file operations, API calls, database queries, web searches, and multi-step reasoning chains. Every tool call was correctly formatted, every parameter was valid, and every chain completed successfully. This is the primary reason Step 3.7 Flash is replacing MiniMax M2.7 as our daily driver model.
Should You Run Step 3.7 Flash Locally or Use the Cloud API?
The answer depends on three factors: data sensitivity, context length needs, and cost at your usage volume.
Run locally if: You handle sensitive client data (we do, as an AI consultancy), need the full 256K context window for long document processing, or have already invested in local hardware like a DGX Spark or Mac Studio. At approximately 27 tokens per second on the DGX Spark, local inference is fast enough for interactive agent workflows, and your data never leaves the device. The Apache 2.0 license means no usage restrictions.
Use the cloud API if: You need maximum throughput (up to 400 tokens per second), want to scale across multiple concurrent requests, or do not have 128GB+ hardware. Cloud pricing is competitive at $0.20 per million input tokens (cache miss), $0.04 per million (cache hit), and $1.15 per million output tokens. Available on StepFun Platform, OpenRouter, NVIDIA NIM, DeepInfra, Fireworks AI, and Modal.
Hybrid approach (what we do): Run the model locally for sensitive client work and long-context tasks. Use the cloud API for high-throughput batch processing where data sensitivity is lower. The consistent model behavior across both deployment paths makes this seamless.
What Are the Local Deployment Options?
StepFun provides multiple quantization options through GGUF format for local deployment:
| Quantization | File Size | Quality | Speed | Best For |
|---|---|---|---|---|
| BF16 | 394GB | Maximum | Slowest | Research, full precision needs |
| Q8_0 | 209GB | Excellent | Fast | High quality, 256GB+ machines |
| Q4_K_S | 112GB | Very Good | Fastest | Best speed/quality tradeoff |
| IQ4_XS | 105GB | Very Good | Fast | 128GB devices, 256K context |
| Q3_K_L | 103GB | Good | Moderate | Tight memory budgets |
| Q3_K_M | 94GB | Good | Moderate | Smallest viable option |
The vision projector adds 4GB (F16 format) on top of these sizes. You also need a 4GB mmproj file for image understanding capabilities.
Supported inference frameworks include llama.cpp (custom step3.7 branch), vLLM (stepfun37 Docker image), and SGLang. Hardware requirements are any device with 128GB or more unified memory: NVIDIA DGX Spark, Mac Studio with M4 Max, AMD Ryzen AI Max+ 395, or equivalent.
For our DGX Spark deployment, we chose IQ4_XS because it leaves enough headroom in the 128GB memory for the vision projector, KV cache at long contexts, and the operating system. Q4_K_S is marginally faster but the 7GB difference in model size means less room for the KV cache at the full 256K context window.
How Do the Cloud API Costs Compare?
Step 3.7 Flash cloud pricing is aggressively competitive, especially given the benchmark performance. Input tokens cost $0.20 per million on cache miss and $0.04 per million on cache hit. Output tokens cost $1.15 per million. Compare this to DeepSeek V4 Flash at $0.22 per million input tokens, and Step 3.7 Flash is both cheaper and more capable on agentic benchmarks.
For teams running AI agents at scale, the cache hit pricing is particularly attractive. Agent workflows often reuse system prompts and tool definitions across many requests, which means a large portion of input tokens will hit the cache at $0.04 per million. This can reduce effective input costs by 80% or more in production agent systems.
The model is available on six platforms: StepFun Platform (direct), OpenRouter, NVIDIA NIM, DeepInfra, Fireworks AI, and Modal. This multi-platform availability provides redundancy and flexibility. If one provider has an outage, you can fail over to another without changing your model configuration.
What Languages Does Step 3.7 Flash Support?
Step 3.7 Flash supports 10 languages: English, Chinese, Japanese, Korean, Arabic, Hindi, German, French, Spanish, and Russian. This multilingual capability is built into the base model rather than bolted on through translation layers, which means you get native-quality reasoning and tool calling in all supported languages.
For businesses operating across the Asia-Pacific region (our home market at Flowtivity), having strong Chinese, Japanese, and Korean support in a single model is valuable. Most frontier models prioritize English performance and treat other languages as secondary. StepFun's Chinese origins likely contribute to the strong multilingual showing here.
What Is Our Final Verdict on Step 3.7 Flash?
After 24 hours of testing on our DGX Spark, Step 3.7 Flash is our new daily driver model. It replaces MiniMax M2.7, which previously scored 97% in our benchmarks. The deciding factors were the 100% tool call success rate, the 23.5 point ClawEval improvement over the previous generation, and the practical reality that this model runs comfortably on hardware we already own.
The model is not perfect. GPT 5.5 and Claude 4 Opus still lead on pure coding benchmarks (SWE-Bench PRO). But for agentic workflows where tool calling reliability, multilingual support, and local deployment matter, Step 3.7 Flash is currently the best option available. The Apache 2.0 license removes any commercial usage concerns.
The broader trend is worth noting: sparse MoE models are reaching a point where they match or exceed dense models at similar parameter counts on practical benchmarks, while being far more efficient to run. Step 3.7 Flash is the strongest evidence of this trend we have seen. When you can run a 198B model that beats most competitors on agentic benchmarks at 27 tokens per second on a desktop device, the economics of AI deployment change fundamentally.
Frequently Asked Questions
Can Step 3.7 Flash run on a consumer laptop?
No. Step 3.7 Flash requires at minimum 128GB of unified memory to load even the smallest quantization (Q3_K_M at 94GB, plus 4GB vision projector and overhead). The minimum viable hardware includes the NVIDIA DGX Spark, Mac Studio with M4 Max (128GB), or AMD Ryzen AI Max+ 395. Consumer laptops with 16-32GB of RAM cannot run this model locally.
How does Step 3.7 Flash compare to DeepSeek V4 Flash?
Step 3.7 Flash beats DeepSeek V4 Flash on both SWE-Bench PRO (56.3 vs 55.6) and ClawEval-1.1 (67.1 vs 43.6), while costing slightly less per token ($0.20/M vs $0.22/M input). The ClawEval gap of 23.5 points is particularly significant for agent use cases. DeepSeek V4 Flash has more total parameters (284B vs 198B) but Step 3.7 Flash's architecture delivers better results with fewer parameters.
What is the best quantization for running Step 3.7 Flash on a DGX Spark?
IQ4_XS (105GB) is the best overall choice for the 128GB DGX Spark. It leaves sufficient headroom for the 4GB vision projector and KV cache while supporting the full 256K context window. Q4_K_S (112GB) offers marginally faster generation but leaves less room for long context KV cache. Q3_K_L (103GB) is an option if you need maximum KV cache space for 256K contexts.
Is Step 3.7 Flash free to use commercially?
Yes. Step 3.7 Flash is released under the Apache 2.0 license, which permits full commercial use, modification, and distribution without licensing fees. You can run it locally on your own hardware at no per-token cost, or use cloud API providers and pay only for the tokens you consume.
What makes Step 3.7 Flash better for AI agents than other models?
Three factors make Step 3.7 Flash stand out for agent workloads. First, it achieved a 100% tool call success rate in our testing, meaning it reliably formats parameters and chains multi-step tool sequences. Second, it scores 67.1 on ClawEval-1.1 (first place), a benchmark specifically designed to evaluate real-world agent performance. Third, the sparse MoE architecture means fast inference at 27+ tokens per second on local hardware, which is essential for interactive agent workflows where latency matters.