I have been building AI systems for real businesses for the last two years. Not demos - actual production systems that handle leads, content, customer comms, and revenue operations. Here is what I learned: the models were never the problem. The plumbing was.
Last updated: 14 June 2026
The Interoperability Thesis: How OpenClaw Turned AI Agents From Hype Into Infrastructure
Or: Why the future of AI isn't a bigger model - it's a better protocol.
The Problem Nobody Wants to Admit
Here's the open secret of the AI industry in 2026: the models are already smart enough.
GPT-5 can reason. Claude can code. Gemini can analyze a spreadsheet. GLM can hold its own against any of them. We've hit a point where raw intelligence isn't the bottleneck - it hasn't been for a while.
The bottleneck is plumbing.
Try to build something real - not a demo, not a Twitter thread, an actual production system that handles revenue operations or runs a content engine or manages a lead pipeline - and you hit the same wall every time:
Nothing talks to anything.
Your CRM lives in HubSpot. Your email runs through Gmail. Your chat is on Slack. Your agent runs on OpenAI's API. Your other agent runs on Anthropic. Your scheduling is in Calendly. Your database is in Postgres. Each one is a walled garden. Each one wants to be your "AI platform." Each one has its own authentication, its own data model, its own way of doing things, and its own opinion about how agents should work.
So what happens? You bolt things together with Zapier and prayers. You write custom glue code for every integration. You maintain brittle webhooks that break when someone at a SaaS company changes an API response format. Your "AI agent" is actually a 500-line Python script with 12 API keys and a TODO comment that says # TODO: handle errors properly.
This isn't agentic operations. This is digital duct tape.
And the cost isn't just technical - it's economic. Every integration you maintain is engineer time. Every context switch between tools is lost productivity. Every agent that can't see what the other agent did is duplicated work. The tax on interoperability is the hidden cost center of the entire AI industry, and almost nobody is talking about it.

The OpenClaw Breakthrough
OpenClaw didn't try to build a better model. They didn't build another wrapper. They did something far more ambitious and far more useful:
They built the protocol layer that makes everything interoperate.
Think about what TCP/IP did for networking. Before TCP/IP, you had IBM networks, DEC networks, ARPANET - all incompatible, all speaking different languages. TCP/IP didn't replace any of them. It sat underneath all of them and gave them a common language. Suddenly, any network could talk to any other network. The internet happened.
OpenClaw is doing the same thing for AI agents.
Any model - Claude, GPT, Gemini, GLM, Qwen, Llama, whatever comes next. Any tool - email, CRM, calendar, browser, database, API, CLI. Any channel - Telegram, Slack, Discord, WhatsApp, web. Any scheduling model - cron, heartbeats, event-driven. Any memory architecture - file-based, vector, graph.
One orchestration layer. One protocol. Everything connects.
This sounds simple because the best infrastructure always sounds simple in hindsight. But the engineering required to make a Claude instance in San Francisco talk to a GLM instance in Singapore, coordinate them on a shared task, persist the session, fork it for a parallel workflow, schedule a follow-up, and remember what happened three weeks later - that's not simple. That's the hard, unglamorous, deeply technical work that nobody on Twitter is posting about because it doesn't fit in a hype thread.
But it's the work that matters.
Why This Makes Agentic Operations Realistic
I've been building AI systems for a while. Here's what I've learned: the difference between an AI demo and an AI product is the difference between a single function call and a system.
Demos are easy. You call an API, you get a response, you show it to someone, they say "wow." Products are hard. Products require state, coordination, error handling, scheduling, memory, handoffs, observability, and - critically - the ability for multiple components to work together toward a goal.
OpenClaw makes products possible. Here's how:
Composable Agents That Actually Hand Off Work
In OpenClaw, agents aren't monolithic. They're composable. A research agent can gather data, hand it to an analysis agent, which hands it to a writing agent, which hands it to a publishing agent. Each one does what it's good at. Each one can be tested independently. Each one can be swapped out without breaking the chain.
This is how human organizations work. Marketing hands off to Sales. Sales hands off to Customer Success. Nobody does everything. The fact that this was hard to do in software until now tells you everything about why agentic ops was stuck in demo mode.
Multi-Model Orchestration
Different models have different strengths. Claude is exceptional at nuanced reasoning and code. GPT-5 is a powerhouse for general tasks. Gemini handles multimodal like nothing else. GLM is fast and cost-effective. Qwen renders text in images better than anyone.
In a world without interoperability, you pick one model and accept its limitations. In OpenClaw's world, you route tasks to the model that handles them best. A customer research task goes to Claude because it reasons well about ambiguity. A high-volume classification task goes to GLM because it's fast and cheap. An image generation task goes to Qwen because the typography is unmatched.
This is multi-model orchestration, and it changes the economics of AI entirely. You're no longer locked into one vendor's pricing, one vendor's rate limits, one vendor's outages. You're free to optimize.
Sessions That Persist, Fork, and Share
OpenClaw sessions aren't ephemeral. They have memory. They can be forked - spun off as parallel branches for different approaches to the same problem. They can be shared - handed from one agent to another, or from a human to an agent, with full context intact.
This means an agent can pick up exactly where another left off. No re-explaining the task. No re-loading the context. No lost state. The session is the unit of work, and it flows through the system like a ticket through a well-run operations team.
Native Scheduling
Cron jobs in OpenClaw aren't bolted on. They're native. An agent can schedule a task, and that task runs as an isolated sub-agent with full context baked in. No dependency on a main session that might get compacted. No fragile in-memory state.
This is the difference between "I'll set a reminder to check on this" and "I've scheduled an autonomous agent to handle this at 9 AM tomorrow with everything it needs to execute independently." The first is a notification. The second is operations.
Memory That Survives
Agents in OpenClaw have persistent memory - daily logs, long-term curated memory, task state. They wake up, read their notes, and pick up where they left off. This sounds obvious, but in most AI systems, every conversation starts from zero. That's not an agent. That's a goldfish.
Memory is what makes an agent get better over time. Not because the model weights change, but because the context accumulates. Lessons learned. Mistakes documented. Preferences internalized. The agent becomes more valuable the longer it runs.
The Easy RL Angle (Or: How Interoperability Makes Learning Natural)
Here's where it gets interesting.
Reinforcement learning has been the "next big thing" in AI for years. The promise: agents that learn from outcomes and improve over time. The reality: RL is hard. It requires carefully designed reward functions, massive training runs, and infrastructure that only a handful of labs can afford.
But OpenClaw makes something remarkable possible: RL by design, not by afterthought.
When everything is interoperable, everything is observable. Every agent action is logged. Every handoff is tracked. Every outcome is measurable. You have a complete trace: this agent did this, handed off to that agent, which did that, which led to this outcome.
That trace is a training signal.
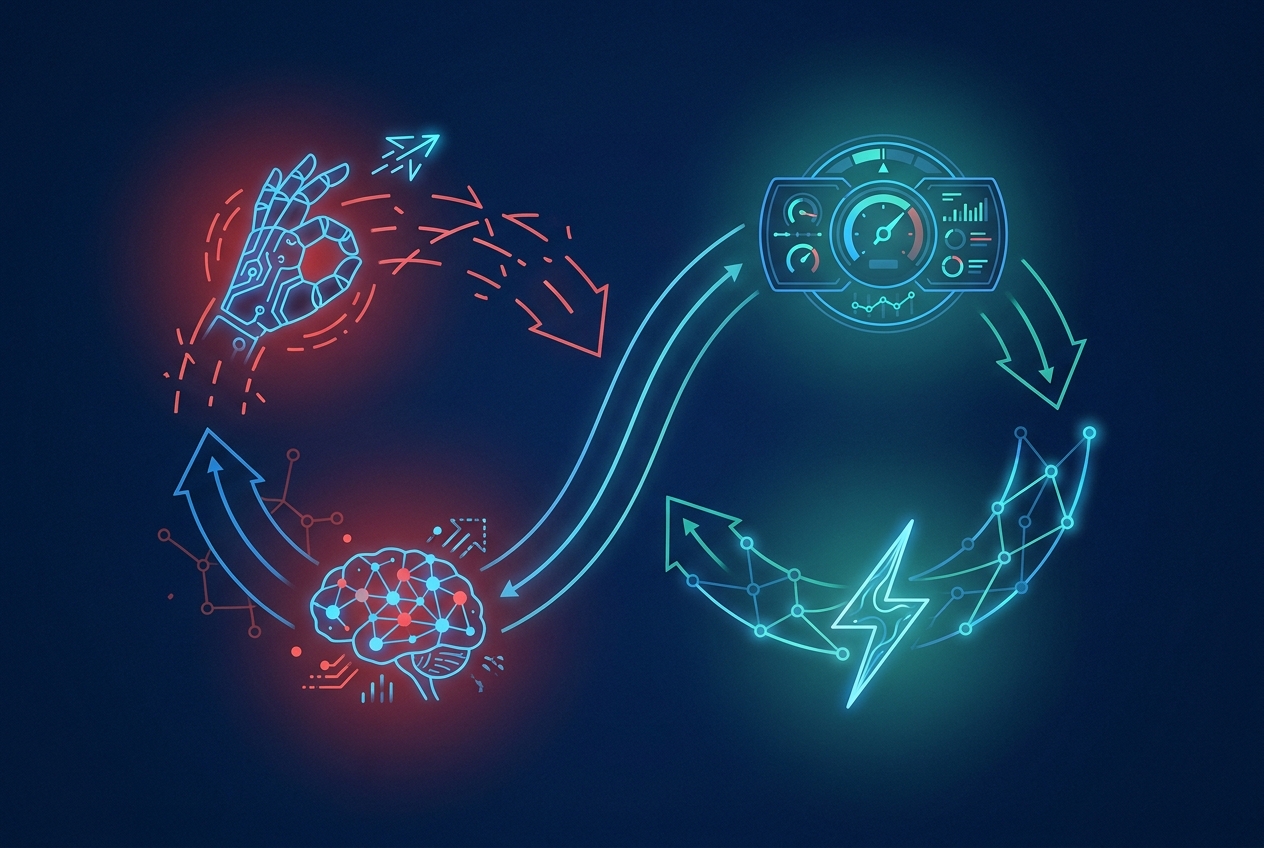
Did the lead convert? Did the email get a reply? Did the content rank? Did the pipeline move? These outcomes are the reward function - and because the system is fully observable (thanks to interoperability), you can propagate that signal back through the chain. The research agent's query strategy gets reinforced or adjusted. The outreach agent's tone gets calibrated. The follow-up agent's timing gets optimized.
This isn't RL in the lab sense - no gradient descent, no GPU clusters. It's RL in the practical sense: feedback flows back through the system, and the system adapts. Agents update their prompts based on what worked. They adjust their workflows based on what failed. They learn which models handle which tasks best, and route accordingly.
The reason RL has been hard for agents isn't that the math is hard. It's that the infrastructure was hard. You can't reinforce a behavior you can't observe, and you can't observe behavior in a system where nothing talks to anything else.
OpenClaw fixes the observation problem by fixing the interoperability problem. And suddenly, RL isn't a research project - it's a natural property of the system.
What This Unlocks for Real Businesses
Let me get concrete. Here's what becomes possible when interoperability is solved:
Revenue Operations: A lead enters the system. A research agent enriches it. A scoring agent evaluates it. An outreach agent contacts it with a personalized prototype. A follow-up agent nurtures it across email and SMS. A scheduling agent books the meeting. A transcription agent captures the call. A CRM agent updates the record. All of this happens autonomously, with human checkpoints where they matter. No engineer required.
Content Engines: A strategy agent identifies topics based on search data. A research agent gathers sources. A writing agent drafts. An editing agent refines. An SEO agent optimizes. A publishing agent ships. A distribution agent syndicates. Each agent uses the model best suited to its task. The content gets better every week because the system learns what resonates.
Customer Success: A monitoring agent watches for churn signals. A triage agent categorizes issues. A resolution agent handles common problems autonomously. An escalation agent routes complex cases to humans with full context attached. Response times drop. Satisfaction rises. The system gets smarter with every ticket.
None of this is theoretical. All of it is the natural consequence of having agents that can coordinate, models that can be mixed and matched, memory that persists, and feedback loops that work.
The companies that figure this out first won't just be "using AI." They'll be operating at a fundamentally different cost structure - the kind of advantage that compounds.
The Bigger Picture: Unix for AI
In the 1970s, Ken Thompson and Dennis Ritchie built something at Bell Labs that would quietly shape the next fifty years of computing. Unix wasn't powerful because it did everything. It was powerful because it did almost nothing - and made it trivial to combine small tools into powerful pipelines.
grep | sort | uniq | head
Each tool does one thing well. The magic is in the pipe - the composition layer that lets you string them together.
OpenClaw is the Unix philosophy applied to AI.
Small, focused agents that do one thing well. A composition layer that lets them hand off work. A protocol that makes them interoperable. A scheduling system that automates the pipelines. Memory that accumulates. Feedback that flows.
Except the tools are intelligent. They can reason about their input, make decisions about their output, and learn from the results. The pipe is alive.
This is the part that the hype machine keeps missing. Everyone's looking for the one model to rule them all - the biggest context window, the most parameters, the highest benchmark score. But the future of AI isn't one ring. It's a network. It's protocol-level interoperability between intelligent components that can be combined, swapped, upgraded, and composed without breaking anything.
OpenClaw understood this. They built the protocol first, not the wrapper. They solved the hard, boring, infrastructure problem that every other platform was pretending didn't exist.
That's not a feature. That's a foundation.
And the companies that build on it will operate in a fundamentally different way - not just "using AI," but running autonomous systems that learn, adapt, and compound value over time.
The interoperability thesis isn't about better AI. It's about AI that actually works together.
That's the game-changer.
The best infrastructure is invisible. You don't notice it - you just notice that everything works. OpenClaw is building the invisible layer that makes AI work.
Want This For Your Business?
At Flowtivity, we build production AI systems on interoperable infrastructure. Not chatbots. Not demos. Real autonomous operations that handle real work - lead pipelines, content engines, customer success, revenue operations.
If you want to see what that looks like for your business, let us talk.
The best infrastructure is invisible. You do not notice it - you just notice that everything works. OpenClaw is building the invisible layer that makes AI work.